A local LLM is a Large Language Model that runs directly on your hardware, without sending your prompts or data to the cloud. This approach unlocks the powerful capabilities of AI while giving you complete control over security, privacy, and customization.
Running an LLM locally means freedom. You can experiment with settings, adapt the model for specific tasks, choose from dozens of architectures, and optimize performance—all without dependency on external providers. Yes, there's an initial investment in suitable hardware, but it often leads to significant long-term savings for active users, freeing you from per-token API fees.
The short answer is: yes, absolutely. A relatively modern laptop or desktop can handle it. However, your hardware specs directly impact speed and usability. Let's break down the three core components you'll need.
While not strictly mandatory, a dedicated GPU (Graphics Processing Unit) is highly recommended. GPUs accelerate the complex computations of LLMs dramatically. Without one, larger models may be too slow for practical use.
The key spec is VRAM (Video RAM). This determines the size of the models you can run efficiently. More VRAM allows the model to fit entirely in the GPU's memory, providing a massive speed boost compared to using system RAM.
Minimum Recommended Specs for 2026
Software & Tools
You'll need software to manage and interact with your models. These tools generally fall into three categories:
The Models Themselves
Finally, you need the AI model. The open-source ecosystem is thriving, with platforms like Hugging Face offering thousands of models for free download. The choice depends on your task: coding, creative writing, reasoning, etc.
Top Local LLMs to Run in 2026
The landscape evolves rapidly. Here are the leading open-source model families renowned for their performance across different hardware configurations.
Leading Universal Model Families
One of the easiest pathways for beginners and experts alike.
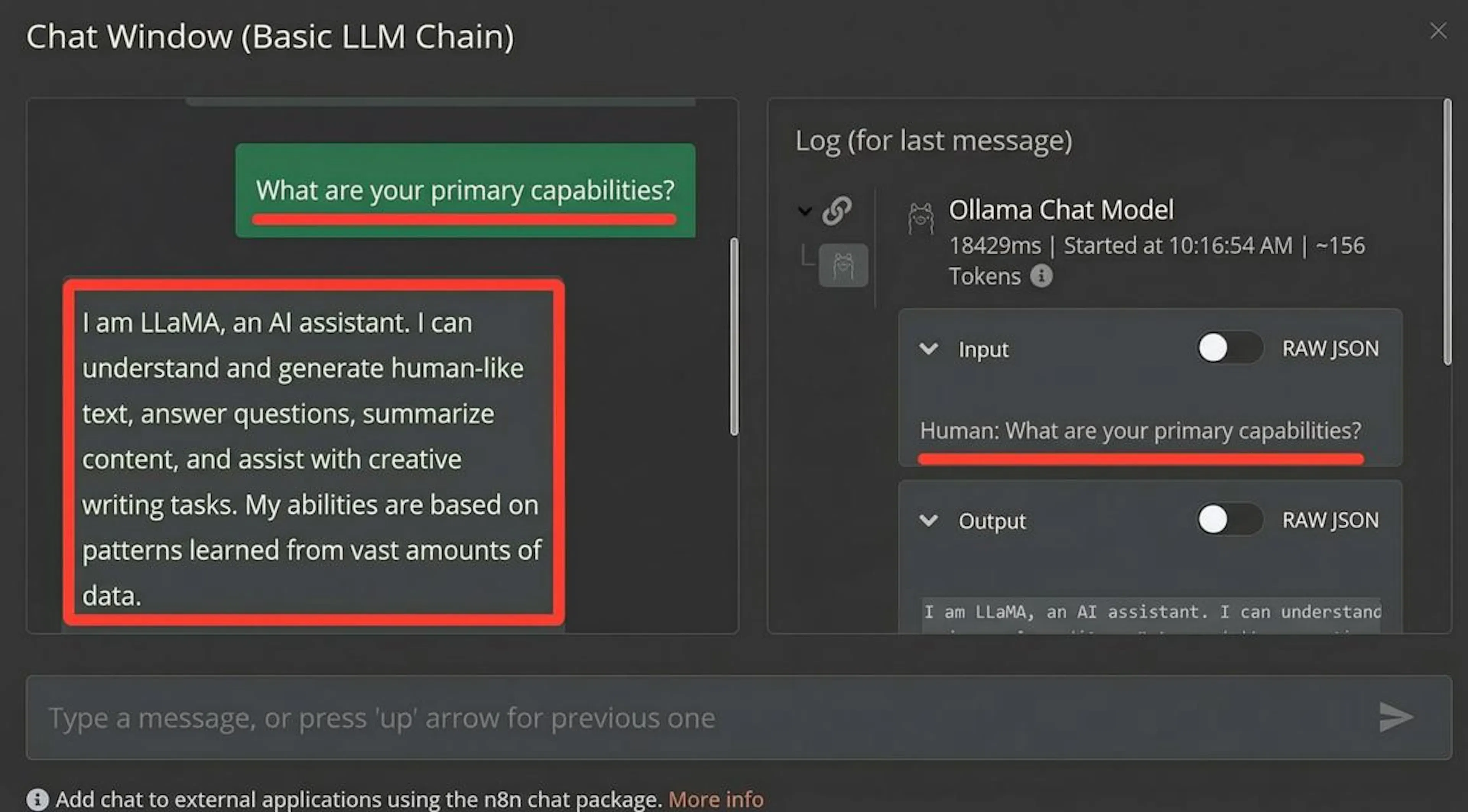
The real power unlocks when you integrate your local LLM into automated workflows. Using a low-code platform like n8n, you can create intelligent automations.
Simple Chatbot Workflow in n8n:
Aspect Local LLM Cloud LLM (e.g., ChatGPT, Claude)
Infrastructure Your computer/server Provider's servers (OpenAI, Google, etc.)
Data Privacy Maximum. Data never leaves your system. Data is sent to the provider for processing.
Cost Model Upfront hardware cost + electricity. No per-use fees. Recurring subscription or pay-per-token (ongoing cost).
Customization Full control. Fine-tune, modify, experiment. Limited to provider's API settings.
Performance Depends on your hardware. High, consistent, and scalable.
Offline Use Yes. No. Requires an internet connection.
Q: How do local LLMs compare to ChatGPT-4o?
A: The gap has narrowed significantly. For specific, well-defined tasks (coding, document analysis, roleplay), top local models like Llama 3.2 70B, Qwen 3 72B, or DeepSeek-R1 can provide comparable quality. The core advantages remain privacy, cost control, and customization. Cloud models still lead in broad knowledge, coherence, and ease of use for general conversation.
Q: What's the cheapest way to run a local LLM?
A: For zero software cost, start with Ollama and a small, efficient model like Phi-4-mini, Qwen2.5:0.5B, or Gemma 3 2B. These can run on CPUs or integrated graphics. The "cost" is then just your existing hardware and electricity.
Q: Which LLM is the most cost-effective?
A: "Cost-effective" balances performance and resource needs. For most users in 2026, models in the 7B to 14B parameter range (like Mistral 7B, Llama 3.2 7B, DeepSeek-R1 7B) offer the best trade-off, running well on a mid-range GPU (e.g., RTX 4060 Ti 16GB).
Q: Are there good open-source LLMs?
A: Yes, the ecosystem is richer than ever. Major open-source families include Llama (Meta), Mistral/Mixtral, Qwen (Alibaba), DeepSeek, Gemma (Google), and Phi (Microsoft). There are also countless specialized models for coding, math, medicine, and law.
Running an LLM locally in 2026 is a powerful, practical choice for developers, privacy-conscious professionals, and AI enthusiasts. It demystifies AI, puts you in control, and can be more economical in the long run.
Ready to start?
The journey to powerful, private, and personalized AI begins on your own machine.

Max Godymchyk
Entrepreneur, marketer, author of articles on artificial intelligence, art and design. Customizes businesses and makes people fall in love with modern technologies.
