Локальная LLM – это большая языковая модель, запущенная прямо на вашем компьютере, без передачи запросов и данных в облако. Такой подход позволяет использовать мощные возможности ИИ, полностью контролируя безопасность и приватность информации.
При локальном запуске вы получаете свободу действий. Можно экспериментировать с настройками, адаптировать модель под конкретные задачи, выбирать разные архитектуры и оптимизировать производительность без зависимости от внешних сервисов. В вашем распоряжении – десятки открытых моделей, каждая из которых подходит под свои сценарии использования.
Да, на старте может потребоваться вложиться в подходящее оборудование. Зато в дальнейшем вы избавляетесь от постоянных расходов на API-запросы. При активном использовании это часто оказывается заметно выгоднее в долгосрочной перспективе.
Логичный вопрос: получится ли запустить LLM на обычном рабочем компьютере? В большинстве случаев – да, если у вас относительно современный ноутбук или десктоп. Но стоит понимать, что характеристики железа напрямую влияют на скорость работы и комфорт использования.
Разберем три ключевых составляющих, которые важны для локального запуска LLM.
Хотя строгой необходимости в этом нет, настоятельно рекомендуется использовать компьютер с выделенной видеокартой. GPU значительно ускоряет вычисления, а без него большие языковые модели могут работать слишком медленно для практического применения.
Ключевую роль играет объем видеопамяти (VRAM). Именно он определяет, какие по размеру модели вы сможете эффективно запускать. Чем больше VRAM, тем выше шанс полностью разместить модель в памяти видеокарты. Это дает огромный прирост скорости, так как доступ к данным в VRAM на порядки быстрее, чем из обычной оперативной памяти.
Помимо GPU, стоит позаботиться и о других ресурсах. LLM активно используют RAM и место на диске. В качестве минимального ориентира можно считать 16 ГБ оперативной памяти и достаточный запас свободного пространства для хранения моделей.
Одного железа недостаточно – потребуется специальное программное обеспечение для запуска и управления моделями. Обычно такие инструменты можно разделить на три группы.
Серверные решения
Они запускают LLM в фоновом режиме, отвечают за загрузку моделей, обработку запросов и генерацию ответов. Это основа всей системы. Примеры: Ollama, Llamafile.
Пользовательские интерфейсы
Визуальные оболочки, через которые удобно общаться с моделью: вводить промпты, читать ответы и настраивать поведение. Они особенно полезны для экспериментов. Примеры: OpenWebUI, LobeChat.
Полноценные решения «всё в одном»
Эти инструменты объединяют сервер и интерфейс, беря на себя всю рутину – от управления моделями до общения с ИИ. Отличный вариант для тех, кто хочет начать без сложной настройки. Примеры: GPT4All, Jan.
Наконец, вам нужны сами модели. Именно они обрабатывают запросы и генерируют ответы. Открытых LLM сегодня очень много, и каждая из них имеет свои сильные стороны: одни лучше пишут код, другие – рассуждают, третьи – создают креативные тексты.
Один из самых популярных источников таких моделей – Hugging Face. Это большой открытый каталог, где можно бесплатно скачать и использовать LLM для локального запуска.
Экосистема локальных LLM развивается стремительно. Практически каждый месяц появляются новые модели или обновления, которые становятся быстрее, умнее или экономичнее по ресурсам.
Сегодня доступно множество мощных open-source решений, рассчитанных на разные задачи и конфигурации железа. Рассмотрим наиболее популярные направления.
Некоторые линейки моделей получили широкое признание благодаря стабильной производительности в самых разных задачах.
Серия Llama, особенно версии 3 и 3.x, известна сильными способностями к логическому мышлению и генерации текста. Модели выпускаются в разных размерах, что упрощает подбор под конкретное железо. Llama 4 уже существует, но ее размеры пока выходят за рамки стандартных домашних систем.
Семейство Qwen включает мультиязычные и код-ориентированные версии. Эти модели хорошо справляются с вызовом инструментов и демонстрируют высокую эффективность относительно своего размера. Qwen 2.5 и Qwen 3 показывают отличные результаты в тестах.
Модели DeepSeek, включая линейку R1, часто выбирают за сильные навыки рассуждений и программирования. Это конкурентоспособные open-source альтернативы закрытым решениям.
Серия Phi делает ставку на компактность. Эти модели достигают высокой производительности при меньшем числе параметров, что делает их отличным выбором для локального запуска на ограниченных ресурсах.
Gemma – легковесные современные модели, основанные на технологиях Gemini. Они оптимизированы для работы на одном GPU. Gemma 3 доступна в разных размерах и показывает сильные результаты с учетом своей компактности.
Mistral AI предлагает эффективные open-source модели, включая Mistral 7B и линейку Mixtral с архитектурой Mixture of Experts. Эти модели известны высокой эффективностью в логике и коде.
Семейство Granite ориентировано на практическое применение и доступно в версиях с разным числом параметров, что удобно для локальных конфигураций.
Помимо обычной генерации текста, существуют модели, заточенные под более сложные сценарии.
Модели для логических рассуждений
Они оптимизированы для анализа, вывода и решения сложных задач. Примеры – DeepSeek-R1 и специальные версии Phi.
Mixture of Experts (MoE)
Такая архитектура активирует только часть параметров под конкретный запрос, экономя ресурсы. Примеры – Qwen 3 и granite3.1-moe.
Модели с вызовом инструментов
Эти LLM умеют взаимодействовать с внешними API и функциями, что лежит в основе агентных систем. Часто используются вместе с LangChain или LlamaIndex.
Визуальные (мультимодальные) модели
Они способны понимать изображения вместе с текстом. Такие модели становятся все более распространенными в open-source-среде.
Иногда лучше выбирать LLM, дообученную под определенную область.
Программирование
Математика и исследования
Креативное письмо
Выбор модели всегда зависит от задач и доступного железа. Лучший способ найти подходящий вариант – тестировать разные решения.
Процесс запуска начинается с выбора подходящей модели, после чего нужно определиться с инструментом для запуска. Часто используют Ollama, но это далеко не единственный вариант.
Ниже – обзор популярных инструментов для локального запуска LLM.
Ollama – это удобный инструмент командной строки, который сильно упрощает загрузку и запуск моделей. Он отлично подходит для быстрого тестирования и часто используется в домашних лабораториях и самохостинге.
Для большего удобства Ollama можно связать с OpenWebUI, получив полноценный графический интерфейс.
Плюсы
Минусы
LM Studio ориентирован на глубокую настройку и эксперименты с моделями. Он позволяет отслеживать производительность, сравнивать конфигурации и даже дообучать LLM.
Плюсы
Минусы
Jan делает упор на безопасность и конфиденциальность. Он может работать как с локальными, так и с удаленными моделями, а также интегрироваться с Ollama и LM Studio.
Плюсы
Минусы
GPT4All ориентирован на простоту и предлагает удобный чат-интерфейс. Встроенная функция LocalDocs позволяет работать с документами полностью локально.
Плюсы
Минусы
NextChat больше подходит для построения сложных диалоговых систем и интеграции с проприетарными моделями вроде ChatGPT или Gemini.
Плюсы
Минусы
Когда базовый запуск освоен, следующий шаг – автоматизация. n8n позволяет встраивать LLM в рабочие процессы, создавать интеллектуальные сценарии и объединять ИИ с другими системами.
n8n использует LangChain, что упрощает создание цепочек промптов, принятие решений и интеграцию с внешними источниками данных. Low-code подход делает настройку доступной даже без глубоких знаний программирования.
Далее вы можете шаг за шагом подключить локальную LLM через Ollama и общаться с ней прямо внутри n8n.
Давайте перейдем от теории к практике и соберем простой, но рабочий сценарий, который позволяет общаться с локальной LLM прямо в n8n.
Суть такая: вы поднимаете модель через Ollama, а затем подключаете ее к n8n и отправляете промпты через удобный чат-интерфейс. В результате ответы ИИ приходят сразу в ваш воркфлоу, и дальше вы можете автоматизировать что угодно.
С Ollama все максимально просто: скачайте установщик под свою систему и установите его. Ollama доступна для Windows, macOS и Linux.
Дальше остается загрузить модель. Например, deepseek-r1:8b:
Загрузка занимает разное время – зависит от выбранной модели и скорости интернета. Для ориентира: одна из версий Llama3 весит около 4.7 ГБ.
После этого можно начать диалог с моделью прямо в терминале.
Теперь настроим простой воркфлоу в n8n, который будет обращаться к вашей локальной модели через Ollama. Вот как примерно выглядит схема, которую мы соберем:
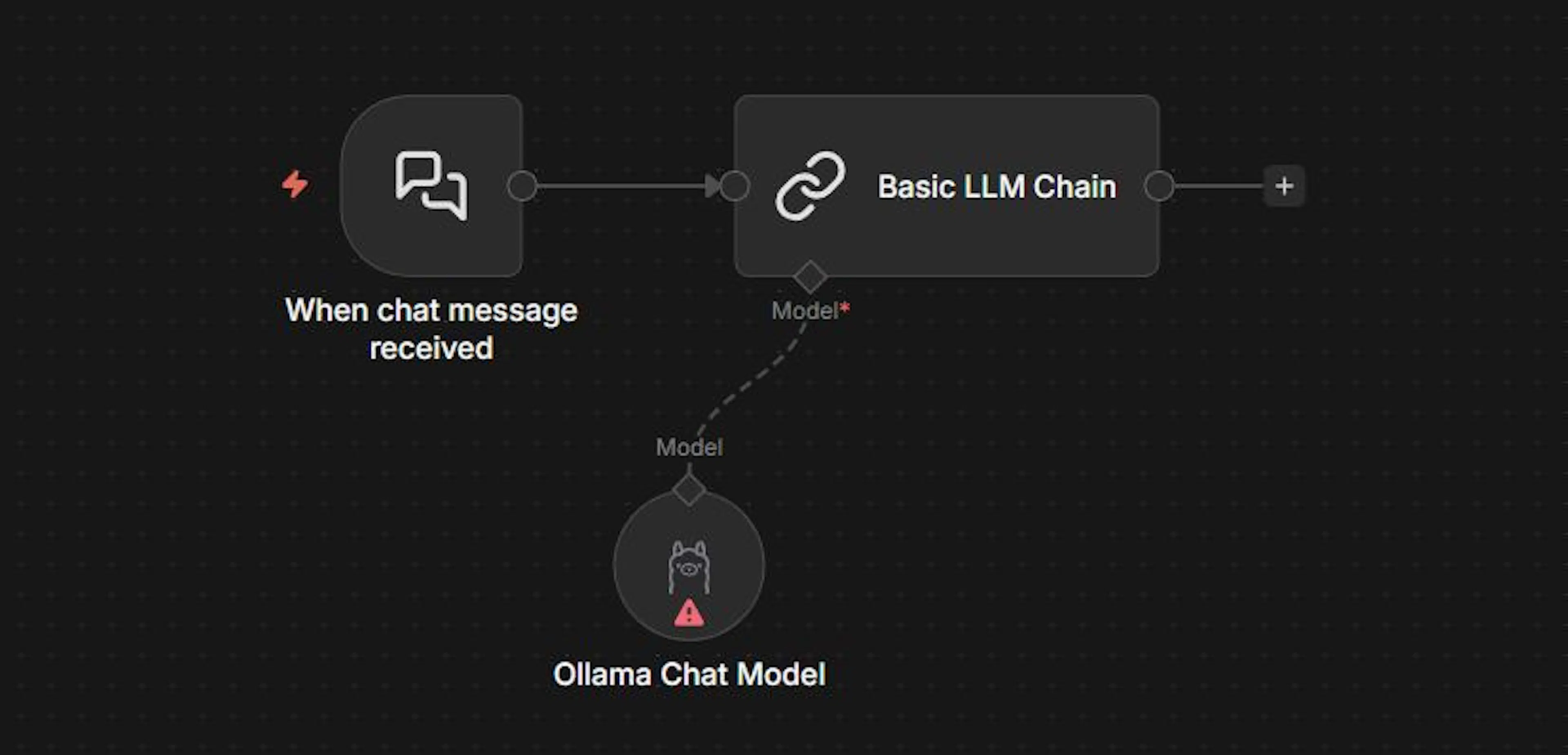
Начните с добавления узла Chat Trigger – это точка входа для чат-интерфейса в n8n. Затем соедините триггер с Basic LLM Chain: в этом узле вы зададите промпт и укажете, какую LLM использовать.
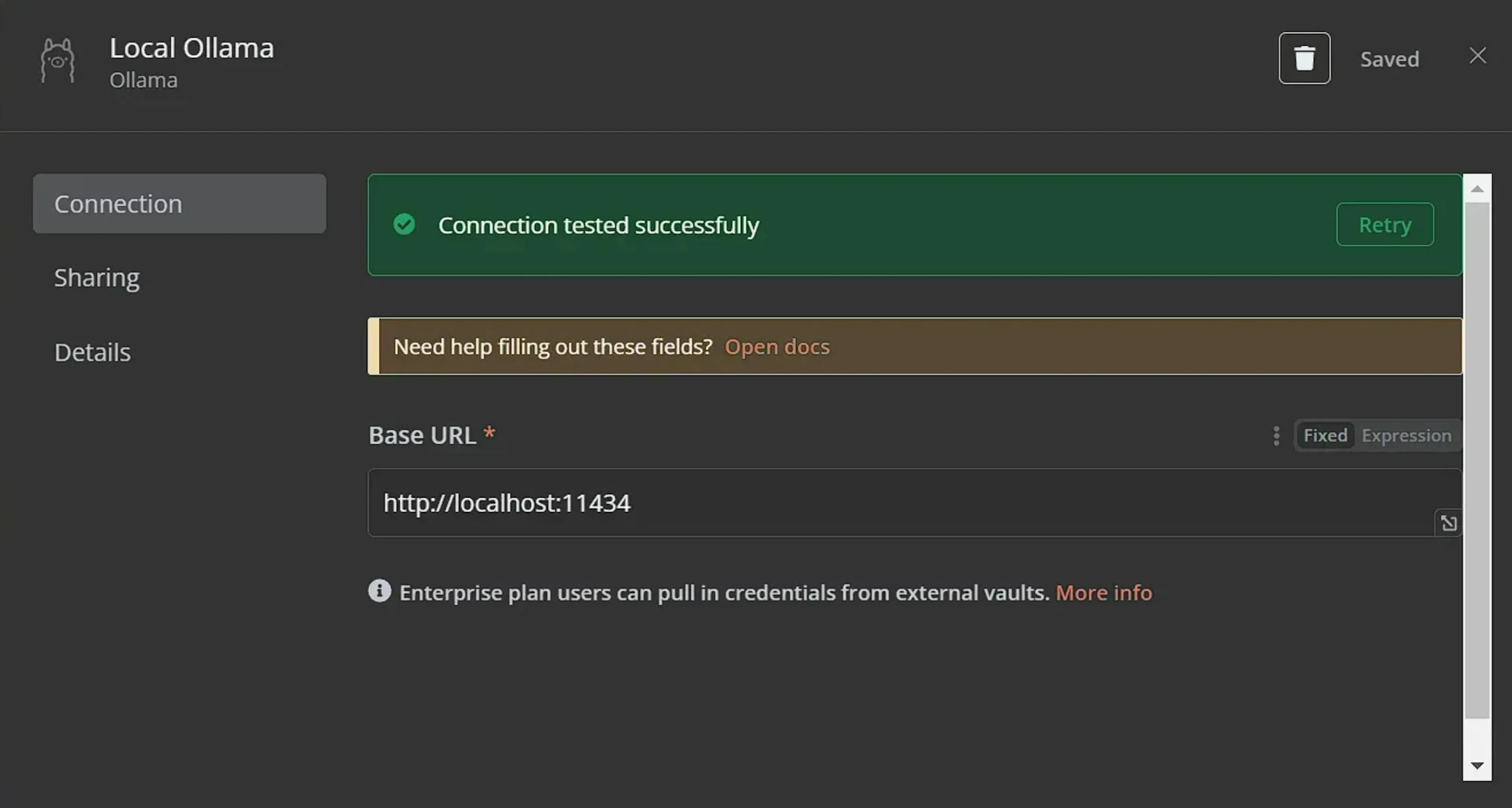
Подключение делается через подузел Ollama Model – и обычно занимает пару минут.
Ollama работает как фоновый процесс и поднимает локальный API на порту 11434.
Если все нормально, вы увидите сообщение “Ollama is running”.
Чтобы n8n могла обращаться к Ollama по localhost, оба приложения должны быть в одной сети. Если n8n у вас запущена в Docker, контейнер нужно стартовать с параметром:
--network=host
Так контейнер получит доступ к портам хост-машины.
В окне подключения Ollama в n8n обычно достаточно оставить настройки по умолчанию:
После подключения в списке Model появятся все модели, которые вы уже скачали через Ollama.
Теперь самое приятное – тест. Нажмите кнопку Chat внизу страницы воркфлоу, отправьте любое сообщение, и локальная модель должна ответить.
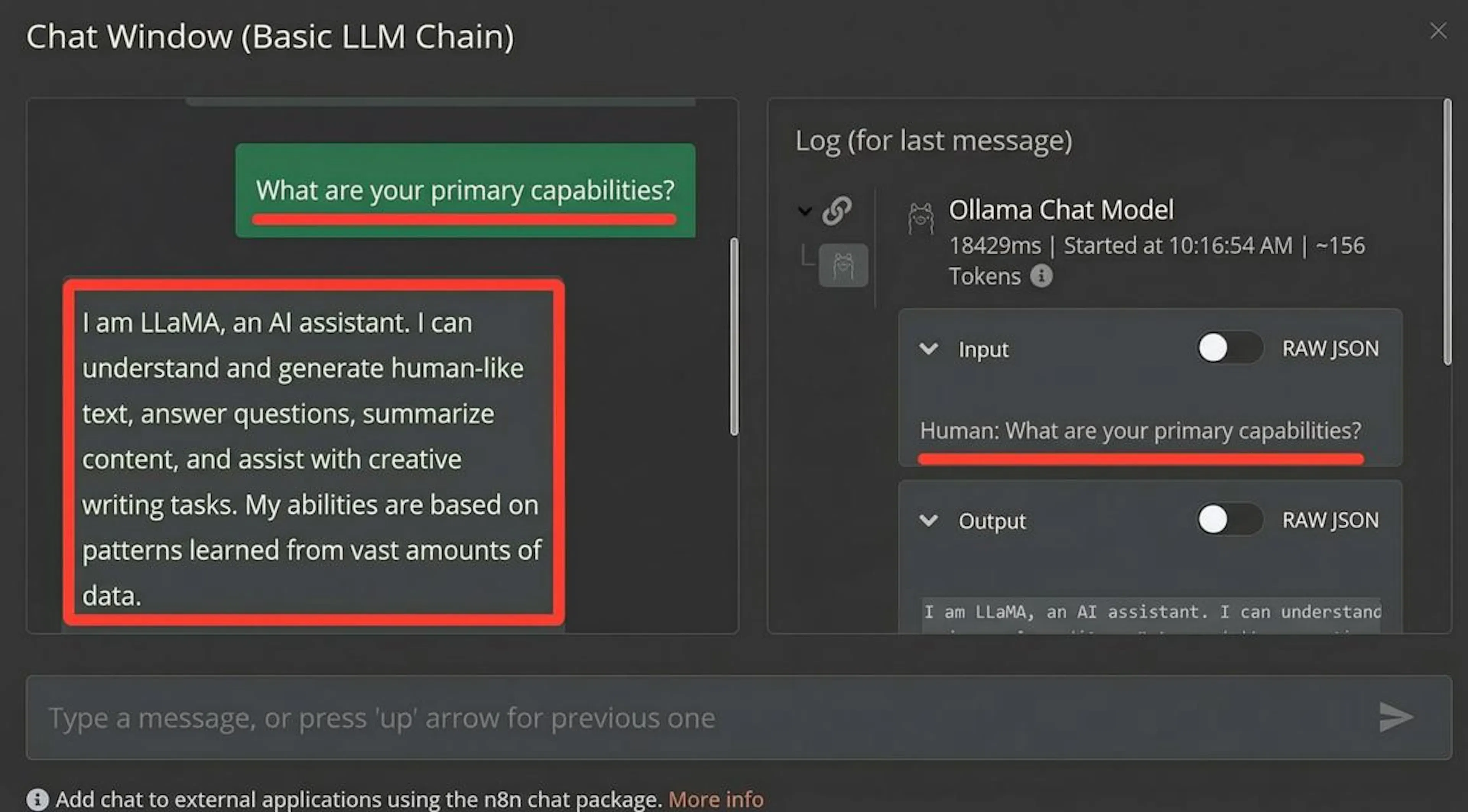
Фактически вы получили чат с LLM внутри n8n – а дальше можно усложнять сценарий: сохранять диалоги, подключать базы данных, отправлять ответы в мессенджеры, строить цепочки промптов и автоматизировать процессы.
Насколько локальные LLM могут быть на уровне ChatGPT?
Локальные модели очень быстро прибавляют в качестве. Многие варианты из семейств Llama, Qwen или Gemma отлично справляются с конкретными задачами – особенно если вы четко формулируете промпты и подбираете модель под сценарий.
Главный плюс локального подхода в том, что приватность здесь встроена по умолчанию: данные остаются у вас, а не уходят на сервера провайдера. Плюс локальные модели часто можно использовать без интернета, гибко настраивать и не платить регулярную подписку.
ChatGPT остается очень сильным решением, но в ряде задач локальная LLM может быть сопоставимой по качеству – а иногда даже удобнее именно из-за контроля и автономности.
Чем отличается локальная LLM от облачной?
Разница упирается в то, где выполняются вычисления и кто управляет данными.
Локальные LLM
работают на вашем компьютере или сервере
конфигурацию железа и софта контролируете вы
промпты, документы и другие данные остаются внутри вашей инфраструктуры
расходы в основном связаны с оборудованием, а не с оплатой каждого запроса
Облачные LLM
запускаются на серверах внешнего провайдера (например, OpenAI или Google)
доступ обычно идет через API или веб-интерфейс
запросы и данные отправляются провайдеру на обработку
стоимость зависит от использования (токены, подписка)
инфраструктуру полностью обслуживает провайдер
Как бесплатно запустить LLM локально?
Если вы хотите начать максимально просто и без затрат, удобным вариантом станет Ollama. После установки (она доступна для macOS, Windows и Linux) вы сможете скачивать и запускать различные открытые модели прямо из терминала.
Например, чтобы поработать с моделью DeepSeek R1, достаточно выполнить команду вроде:
ollama pull deepseek-r1:14b
Так вы загрузите версию модели с 14 миллиардами параметров. После завершения загрузки можно сразу начать диалог, запустив:
ollama run deepseek-r1
Ollama берет на себя управление файлами моделей и предоставляет простой API, скрывая большую часть технических деталей. Полный список доступных моделей можно посмотреть в библиотеке Ollama.
Какая LLM обходится дешевле всего?
Хотя большинство open-source моделей можно скачать бесплатно, фактическая стоимость локального запуска определяется другим – требованиями к железу и расходами на электроэнергию. В этом контексте «дешевые» модели – те, которым нужно меньше ресурсов.
Для максимальной производительности модель (или значительная часть ее параметров) должна помещаться в видеопамять GPU. Чем больше модель, тем больше требуется VRAM. Например, для комфортного запуска модели размером около 20 ГБ обычно нужна видеокарта с минимум 24 ГБ VRAM – вроде RTX 4090 или RTX 3090.
Модели меньшего размера – примерно от 1 до 8 миллиардов параметров – гораздо экономичнее в эксплуатации. Они требуют меньше видеопамяти и вычислительной мощности и вполне уверенно работают на среднем потребительском оборудовании. Примеры таких моделей:
Более крупные модели – от 14 миллиардов параметров и выше – потенциально дают лучшие результаты, но требуют гораздо более мощного железа. Чаще всего это топовые потребительские видеокарты вроде RTX 4090 (24 ГБ), RTX 5090 (32 ГБ) или AMD Radeon RX 7900 XTX (24 ГБ). В случае самых больших моделей могут понадобиться профессиональные GPU (например, NVIDIA A100 или H100) либо даже несколько видеокарт одновременно, что сильно повышает стоимость локального запуска.
При этом видеокарты среднего класса – такие как RTX 3060 (12 ГБ), RTX 4060 Ti (16 ГБ) или RTX 4070 (12 ГБ) – нередко отлично справляются с компактными моделями. Даже современные интегрированные GPU или чипы Apple Silicon (серия M) способны запускать небольшие LLM, пусть и с меньшей скоростью по сравнению с дискретными видеокартами.
Как с ценами обстоят дела у облачных LLM?
В облаке логика схожа: чем выше возможности модели, тем дороже она обходится.
Обычно провайдеры предлагают несколько уровней:
Быстрые и более дешевые модели – это облегченные или оптимизированные версии. Они стоят меньше за запрос, но могут уступать в сложных рассуждениях и тонких задачах.
Флагманские и более дорогие модели – крупные и мощные решения, обеспечивающие максимальное качество, но с более высокой ценой за использование.
Есть ли LLM с открытым исходным кодом?
Да, и их становится все больше. Экосистема open-source LLM активно развивается, а крупные компании и исследовательские команды регулярно публикуют свои модели под открытыми лицензиями.
Среди популярных примеров:
Кроме универсальных решений, существует множество специализированных open-source моделей, созданных под конкретные задачи:
Такой выбор позволяет подобрать LLM практически под любую задачу и аппаратную конфигурацию.
Локальный запуск LLM – это не эксперимент ради эксперимента, а вполне практичное решение. Он подходит тем, кто ценит приватность, хочет сократить расходы или глубже разобраться в работе ИИ.
Современные инструменты сделали этот процесс доступным даже на потребительском оборудовании. А связка с платформами автоматизации вроде n8n открывает путь к созданию полноценных ИИ-приложений прямо у себя дома.
Что дальше?
Если тема локальных LLM вам откликнулась, следующий логичный шаг – практика. Изучите примеры создания локальных ИИ-агентов, работу с векторными базами данных и интеграцию LLM в реальные рабочие процессы. Это лучший способ превратить теорию в полезный инструмент.

Максим Годымчук
Предприниматель, маркетолог, автор статей про искусственный интеллект, искусство и дизайн. Кастомизирует бизнесы и влюбляет людей в современные технологии.
