Озвучка нейросетью — технология, которая преобразует текстовый контент в аудиодорожку через алгоритмы искусственного интеллекта. Если раньше синтез речи звучал механически, то современные нейросети создают голоса, которые на слух почти не отличаются от живого диктора. Это возможно благодаря LLM-based моделям, которые понимают контекст, расставляют правильные ударения и передают нужные интонации.
Почему озвучка с помощью нейросети стала критически важной в 2026 году:
Экономия времени и бюджета. Создание аудиоверсии видео раньше требовало неделю работы студии и выплат дикторам. Теперь это занимает минуты, а стоимость снижается в 10-20 раз. Для YouTube-канала с 100 видео в год разница в расходах составляет тысячи долларов.
Масштабируемость контента. Один сценарий озвучивают на 20 языках за час благодаря озвучке текста ИИ. Полиглотские нейросети поддерживают редкие акценты и диалекты, что раньше было невозможно.
Доступность для всех. Не нужно специального оборудования — достаточно браузера и текста. Озвучивание текста нейросетью доступно фрилансерам, студентам, малому бизнесу и крупным корпорациям одинаково.
Персонализация и контроль. Вы можете клонировать собственный голос или создать уникальный персонаж. Генерация речи ИИ позволяет управлять эмоциональным окрасом, скоростью произношения и паузами — свойства, которые раньше зависели от актерского мастерства.
Сегодня озвучка нейросетью применяется в подкастах, аудиокнигах, рекламе, корпоративных видео, образовательных курсах и даже в видеоиграх. Эта технология больше не маргинальный инструмент — это стандарт производства контента на профессиональном уровне.
Процесс озвучки нейросетью состоит из трех этапов. Понимание этого механизма помогает выбрать нужный сервис и правильно подготовить материал.
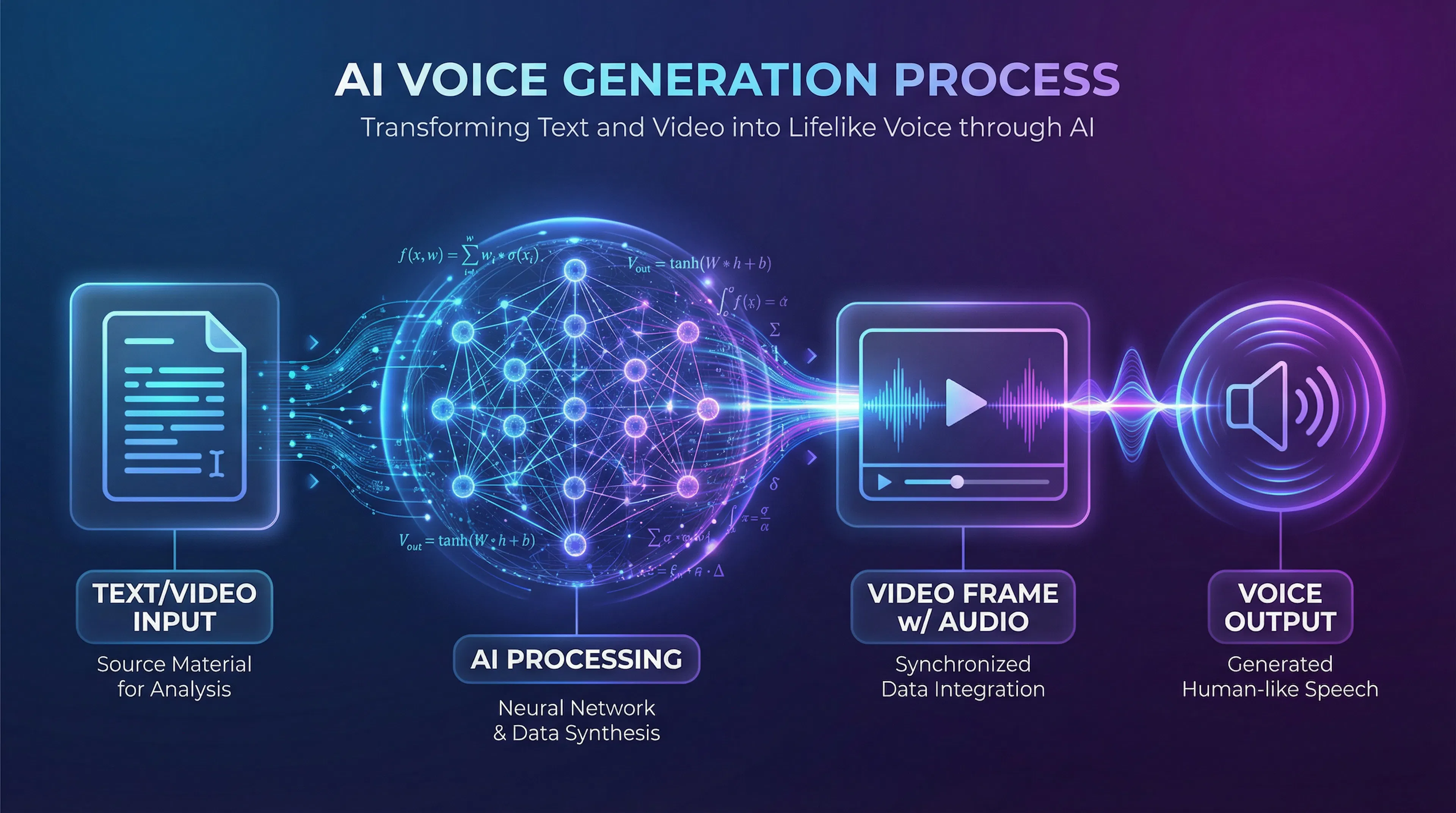
Этап 1: Анализ текста и понимание контекста
Когда вы загружаете сценарий в сервис озвучки, нейросеть сначала разбирает его структуру. Алгоритм распознает пунктуацию, числа, аббревиатуры и определяет, где должны быть паузы. Например, точка — это полная пауза, запятая — короткая остановка, восклицательный знак — вскрик или усиление голоса.
На этом же этапе модель анализирует смысл предложения. Если фраза: "Что ты хочешь?", то голосовой синтез нейросети поднимет интонацию в конце, имитируя живой вопрос. Классический TTS просто прочитал бы монотонно.
Продвинутые системы на основе больших языковых моделей (LLM) даже "угадывают" эмоциональный окрас текста. Грустная история получит более медленный темп, рекламный текст — энергичность и уверенность в голосе.
Этап 2: Синтез звуковой волны
После анализа начинается генерация речи ИИ. Нейросеть трансформирует проанализированный текст в акустические характеристики: высоту тона, громкость, длительность звуков, тембр голоса. Этот процесс называется моделированием речевого сигнала.
Современные сервисы используют технику клонирования голоса: вы загружаете образец вашего голоса или голоса актера (несколько минут аудио), и модель воспроизводит его в контексте нового текста. Это означает, что ваш персональный голос читает совершенно новый сценарий, сохраняя характерные черты дикции и тембра.
Этап 3: Обработка и экспорт
Готовую аудиодорожку система обрабатывает: убирает артефакты, выравнивает громкость, иногда добавляет фоновые звуки. Вы получаете файл в формате MP3, WAV или другом, готовый к встраиванию в видео или публикации как подкаст.
Если вы озвучиваете видео, сервис синхронизирует звук с видеорядом. Продвинутые платформы автоматически определяют, где должны быть паузы озвучки, чтобы совпадать с переходами сцен или появлением текста на экране.
От текста к готовому файлу: схема работает так же.
Процесс озвучки видео нейросетью похож: вы загружаете видеофайл, сервис извлекает текст из субтитров или вы его вставляете вручную. Затем происходит озвучивание, и готовая аудиодорожка автоматически подкладывается под видео с синхронизацией по времени.
Главное отличие от озвучки только текста — система должна учитывать визуальный контекст. Если в видео персонаж открывает рот в 10-й секунде, озвучка должна начинаться примерно в то же время, а не раньше или позже.
Озвучка с помощью нейросети вышла за рамки экспериментов и стала рабочим инструментом в десятках отраслей.
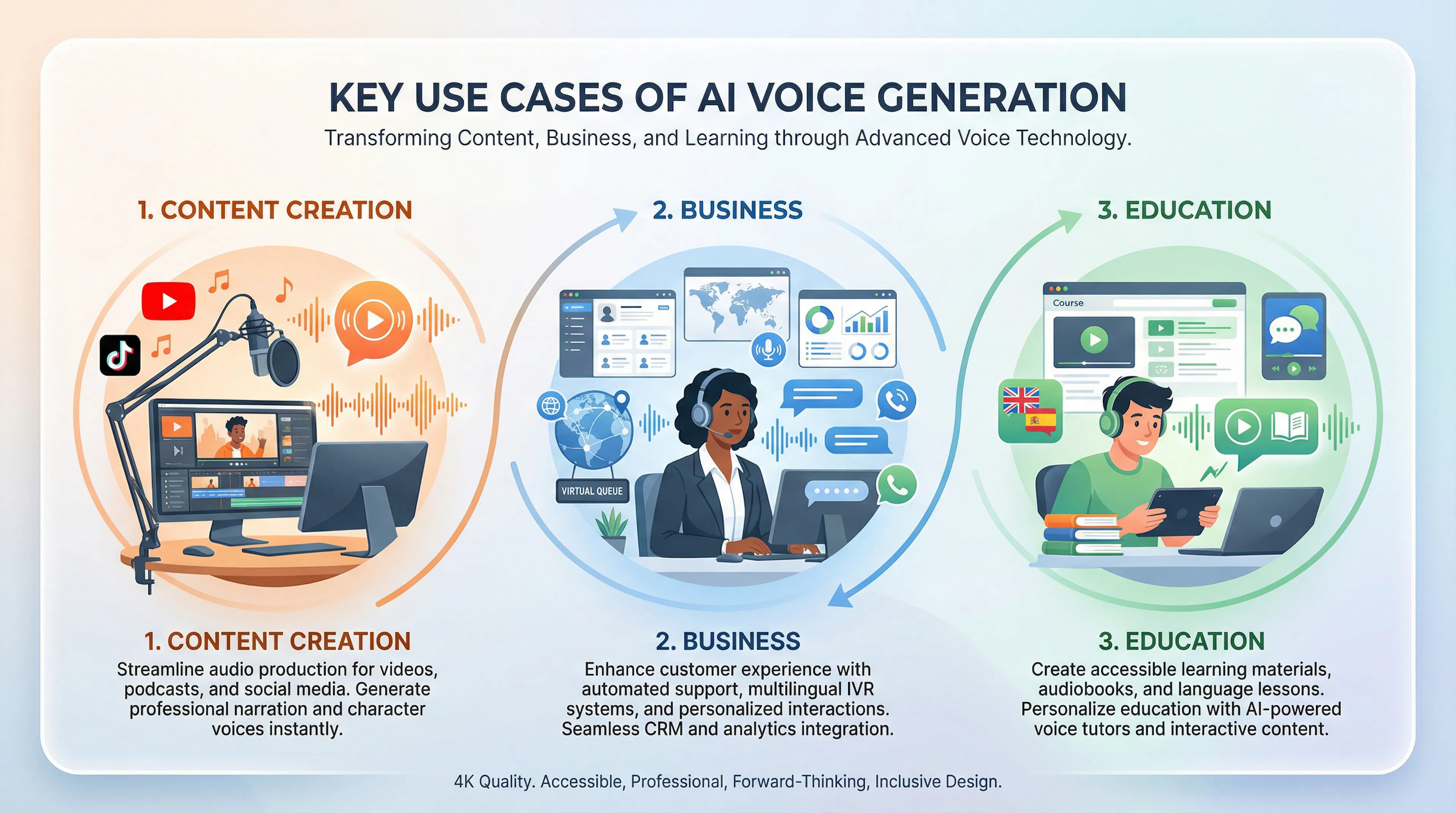
YouTube и стриминг-контент
Блогеры используют озвучивание текста нейросетью для ускорения выпуска видео. Вместо записи собственного голоса они загружают сценарий и получают готовую озвучку за пять минут. Для каналов с еженедельными выпусками это сэкономит месяцы работы в год. Популярные сервисы позволяют выбрать голос (мужской, женский, разные акценты), что дает творческую гибкость.
Подкасты и аудиокниги
Авторы создают подкасты без студийного оборудования. Синтез речи ИИ позволяет озвучить целую книгу за день, тогда как профессиональная запись заняла бы недели. Платформы вроде Audiobooks.com и Storytel активно используют нейросети для озвучки именно потому, что это значительно снижает входные барьеры для независимых авторов.
Корпоративный сектор и IVR
Компании вкладывают в голосовой синтез нейросети для автоответчиков и внутренних систем. Колл-центры теперь могут предложить абонентам вежливого робота вместо скучного механического голоса. Озвучка текста нейросетью используется и для создания корпоративных видеоинструкций: руководство по охране труда, обучение сотрудников, presentации для инвесторов.
Образование и e-learning
Платформы онлайн-обучения (Coursera, Udemy, внутренние корпоративные LMS) применяют озвучивание документов нейросетью для создания аудиоверсий лекций. Студенты могут слушать материал в дороге, во время тренировки или перед сном. Это особенно помогает людям с нарушениями зрения и просто тем, кто лучше усваивает информацию на слух.
Локализация и перевод
Киностудии и разработчики игр используют озвучку видео нейросетью для дубляжа на разные языки. Вместо привлечения актеров для каждого языка достаточно одной записи оригинального голоса, и нейросеть озвучит фильм на испанском, немецком, китайском. Персонаж звучит узнаваемо, но говорит правильно на целевом языке.
Маркетинг и реклама
Агентства создают рекламные ролики с озвучкой ИИ, сокращая time-to-market. Вместо согласования с дикторами и записи в студии можно быстро протестировать несколько вариантов озвучки и выбрать лучший. Генерация речи ИИ дает возможность экспериментировать с тоном: та же фраза звучит по-разному в зависимости от выбранного голоса и эмоционального стиля.
Озвучка нейросетью применяется к разным типам контента, и каждый вид имеет свои особенности, требования к качеству и выбор инструментов.
Основная разница между видами озвучки заключается в формате исходного материала и целях использования. Озвучивание статического текста требует минимум настроек — загрузил текст, выбрал голос, получил аудиофайл. Озвучка видео нейросетью сложнее: нужна синхронизация звука с видеорядом, учет визуальных элементов и правильная расстановка пауз по времени.
Подкасты и аудиокниги — промежуточный вариант. Здесь важнее всего качество голоса и естественность речи, потому что слушатель сконцентрирован именно на аудио. IVR-системы и голосовые боты — отдельная категория: тут нужны короткие, четкие фразы, понимание контекста диалога и быстрая обработка запросов.
Разберемся в каждом виде подробнее, чтобы выбрать оптимальный сервис для вашей задачи.
Озвучка текстового контента — самый простой способ начать работу с озвучкой ИИ. Сценарий не требует синхронизации с видео, вы полностью контролируете темп и тон речи.
Когда выбирать озвучку текста
Эта форма подходит для статей в блогах, которые читатели хотят слушать в фоне. Журналист пишет материал, загружает его в сервис озвучки нейросетью, и статья становится подкастом. Читатели могут изучать контент на комьютинге или тренировке.
Документы — приказы, инструкции, служебные записки — озвучивают компании для внутреннего использования. Сотрудник, вместо того чтобы читать 10-страничный PDF, слушает аудиоверсию. Озвучивание документов нейросетью экономит время и повышает retention информации.
Сценарии для видео тоже начинают с озвучки текста. Вы пишете речь для видеоблога или ролика, озвучиваете её, а потом под готовую аудиодорожку подбираете визуальный контент. Это называют режимом "сценарий первым" — экономнее, чем снимать видео и потом искать голос.
Как работает процесс
Загружаете текст в редактор сервиса (Voicemaker, ElevenLabs, GPTUNNEL). Сразу видите список доступных голосов — выбираете подходящий по полу, возрасту, акценту. Настраиваете скорость речи (обычно от 0.5x до 1.5x), эмоциональный стиль (если сервис это поддерживает) и нажимаете "Генерировать". Генерация речи ИИ занимает от нескольких секунд до нескольких минут в зависимости от объема текста.
Результат скачиваете в MP3, WAV или другом формате. Некоторые сервисы добавляют возможность редактирования: если какое-то слово озвучилось неправильно, вы можете переозвучить только этот фрагмент.
Особенности и советы
Качество зависит от качества самого текста. Если в тексте много опечаток, странной пунктуации или сложных слов, озвучка текста нейросетью может звучать странно. Сервис озвучивает то, что написано: если написано "1000", нейросеть прочитает "один ноль ноль ноль", а не "тысяча".
Для длинных текстов (более 5000 символов) сервис может разбить озвучку на части. Убедитесь, что паузы между частями естественные и текст звучит как единое целое.
Лучшие сервисы для озвучки текста предлагают большой выбор голосов на русском языке и поддерживают различные эмоциональные окраски. Это позволяет адаптировать озвучку под жанр: деловой тон для инструкций, дружелюбный для блога, серьезный для аналитики.
Озвучка видеоконтента сложнее, чем озвучка текста, потому что звук должен совпадать с видеорядом. Но технология развилась настолько, что синхронизация часто происходит автоматически.
YouTube и длинные форматы
На YouTube озвучка видео нейросетью экономит месяцы работы. Вместо записи собственного голоса (микрофон, звукозапись, монтаж) вы загружаете видео с субтитрами или вставляете сценарий — и сервис озвучивает ролик. Озвучивание видео нейросетью позволяет выбрать голос, который лучше подходит вашему контенту: для разборов — серьёзный, для лайфстайла — дружелюбный, для обучения — чёткий и медленный.
Авторы каналов про игры, технику, образование активно используют эту технологию. Вместо того чтобы сидеть с микрофоном и переписывать текст, они просто пишут сценарий, и озвучка видео ИИ звучит профессионально.
TikTok и Reels: короткие форматы
Для коротких видео (15–60 секунд) озвучка ещё проще. Озвучка ИИ на TikTok часто встроена в приложение — вы выбираете один из готовых голосов и ролик озвучивается за пару тапов. На Reels (Instagram) и YouTube Shorts процесс похож.
Короткие ролики требуют быстрого темпа и чёткой дикции. Генерация речи нейросетью здесь работает лучше всего, потому что нет времени на "деревянные" части озвучки — всё должно быть лаконично и энергично.
Синхронизация и техника
Когда вы озвучиваете видео нейросетью, алгоритм анализирует видеоряд и автоматически расставляет паузы в озвучке. Если в видео есть текст на экране или переход сцены, система старается совместить озвучку с этими моментами. Если синхронизация неидеальна, большинство сервисов позволяют вручную сдвинуть звук на несколько миллисекунд.
Важный момент: озвучивание видео нейросетью работает лучше, если ваш исходный сценарий чётко структурирован. Абзацы, пунктуация, логические паузы — всё это помогает сервису правильно озвучить материал.
Кейсы применения
Авторы образовательных каналов озвучивают обучающие видео. Маркетологи создают рекламные ролики с озвучкой нейросетью — это быстрее и дешевле, чем нанимать актера. Разработчики игр дублируют видео на разные языки, сохраняя узнаваемый голос главного персонажа благодаря клонированию голоса.
Для подкастов и аудиокниг качество озвучки критично. Слушатель сосредоточен только на звуке, поэтому любой артефакт или неестественность будет заметна. Здесь озвучка нейросетью должна звучать максимально живо.
Подкасты: новые возможности
Создатели подкастов часто выбирают между записью собственного голоса и использованием озвучки текста ИИ. Если вы пишете сценарий (вместо импровизации), то озвучка нейросетью даёт несколько преимуществ: нет необходимости в студии, микрофоне и звукорежиссёре. Вы пишете, загружаете в сервис, получаете готовый эпизод.
Озвучивание подкастов нейросетью работает особенно хорошо для информационных подкастов (новости, аналитика, обучение). Для развлекательных форматов (юмор, разговоры) живой голос все ещё предпочтительнее, хотя новые модели уже улавливают шутки и меняют интонацию.
Платформы вроде Podcastle и других сервисов специально оптимизированы для подкастеров. Они позволяют выбрать голос, который подходит тону вашего шоу, и быстро озвучить целый выпуск.
Аудиокниги: масштабирование литературы
Озвучка аудиокниги нейросетью — это революция для независимых авторов. Раньше профессиональная запись книги стоила тысячи долларов и занимала недели студийной работы. Теперь автор может загрузить текст и получить готовую аудиокнигу за день.
Качество современной озвучки позволяет конкурировать с профессиональными изданиями. Озвучивание текста нейросетью для аудиокниг поддерживает разные эмоциональные стили: грустную сцену нейросеть прочитает медленнее и тише, напряженный момент — быстрее и громче.
Платформы типа Google Play Books и Amazon Audible начали предлагать авторам встроенную озвучку. Это означает, что каждая загруженная книга автоматически получает аудиоверсию, доступную слушателям.
Требования к качеству
Для подкастов и аудиокниг выбор голоса критичен. Мужской голос подходит для детективов и бизнес-литературы, женский — для романов и лайфстайла. Синтез речи нейросетью должен поддерживать различные акценты и диалекты, если в тексте много диалогов персонажей с разными характерами.
Темп речи тоже важен. Для аудиокниг рекомендуется 0.9–1.1x скорость (медленнее, чем в видео). Слушатель должен иметь время, чтобы усвоить информацию и представить себе сцену.
Монетизация
Авторы зарабатывают на аудиокнигах, озвученных озвучкой ИИ. Комиссия платформ ниже, чем если бы работал живой диктор, поэтому маржинальность выше. Это особенно выгодно для независимых авторов и малых издательств.
IVR (Interactive Voice Response) — это голосовые системы, которые вы слышите, когда звоните в банк или техподдержку. Раньше это были неживые робот-голоса, которые раздражали слушателей. Сегодня озвучка с помощью нейросети превратила IVR в более дружелюбный и эффективный инструмент.
Как работают голосовые меню на базе ИИ
Когда вы звоните в компанию, система озвучивает приветствие: "Добро пожаловать, выберите опцию". Раньше это были записи живых дикторов или монотонные синтетические голоса. Теперь озвучивание текста нейросетью создает голоса, которые звучат естественно, вежливо и даже с некоторым сочувствием.
Озвучка ИИ для IVR-систем позволяет компаниям:
Голосовые боты и помощники
Генерация речи ИИ применяется в чат-ботах и голосовых ассистентах. Когда бот отвечает на вашу фразу, озвучивание происходит в реальном времени. Это требует быстрого синтеза и высокого качества — система не может ждать 10 секунд, пока озвучится ответ.
Сервисы типа Google Assistant и Яндекс.Алиса используют продвинутые озвучка нейросеть модели, которые не просто читают текст, а понимают контекст диалога. Если вы спрашиваете грустным голосом, ассистент ответит участливо. Если вы спешите, ответ будет быстрее.
Кейсы в России и мире
Российские банки внедряют озвучивание текста нейросетью в звонки о подозрительных операциях. Вместо роботического "Ваша карта заблокирована" система говорит: "Внимание, мы обнаружили подозрительную активность". Это снижает количество людей, которые вешают трубку, думая, что это спам.
Call-центры используют озвучка ИИ для автоответчиков и распределения звонков. Голос информирует: "Все операторы заняты, ваш номер в очереди". Благодаря естественности речи люди дольше ждут вместо того, чтобы повесить трубку.
Техническое преимущество
Озвучка видео нейросетью и голосовые системы требуют одной технологии — быстрого синтеза. Но для IVR и ботов важнее всего минимальная задержка. Сервис должен озвучить ответ за миллисекунды, иначе диалог прерывается и пользователь теряет интерес.
Современные платформы типа Google Cloud Text-to-Speech и Amazon Polly обеспечивают синтез за 100–500 миллисекунд. Это достаточно быстро, чтобы разговор с ботом казался естественным.
Затраты и выгода
Компания, которая озвучивает IVR-систему озвучкой нейросетью, экономит на записи профессиональных дикторов. Если меню нужно обновить, нет необходимости нанимать студию — достаточно изменить текст в системе, и новая озвучка готова за минуты.
Чтобы правильно выбрать сервис озвучки и понять его возможности, полезно знать, как устроена технология изнутри. За последние пять лет синтез речи прошел путь от механических голосов к практически неотличимым от человека.
Классический TTS: история и принцип работы
Text-to-Speech (TTS) — технология преобразования текста в речь — появилась в 1960-х годах. Первые системы были простыми: алгоритм разбивал текст на фонемы (звуки) и воспроизводил их последовательно. Результат звучал как робот, читающий по слогам.
Классический TTS работает в два этапа. На первом этапе система анализирует текст: разбивает на слова, определяет ударения, понимает, как произносятся числа и аббревиатуры. На втором этапе синтезирует звук: преобразует фонемы в акустический сигнал с помощью заранее записанных фрагментов голоса или математических моделей.
Результат был предсказуем и понятен, но звучал неестественно. Нейросетевой синтез изменил это.
Нейросетевой синтез речи: революция качества
В начале 2010-х появились первые нейросетевые модели синтеза речи. Вместо правил и фонем система обучалась на примерах живой речи и училась предсказывать, как должна звучать каждая фраза в контексте.
Синтез речи нейросеть работает так: модель анализирует не просто текст, а его смысл. Если предложение: "Что ты имеешь в виду?" — нейросеть понимает, что это вопрос, и поднимает интонацию в конце. Если: "Стоп." — понимает, что это команда, и делает голос более резким.
Ключевое отличие от классического TTS — нейросеть учится на данных, а не на жестких правилах. Она может воспроизвести паузы, дыхание, даже микровибрации голоса, которые делают речь живой. Это привело к созданию голосов, которые на слух почти неотличимы от человеческих.
LLM-based синтез речи: новое поколение озвучки
В 2024–2025 годах появилось новое поколение синтеза — на основе больших языковых моделей (Large Language Models, LLM). Вместо двух отдельных нейросетей (одна анализирует текст, вторая синтезирует звук) используется единая модель, которая понимает контекст глубже.
Озвучка нейросетью на базе LLM позволяет:
Например, слово "замок" может быть прочитано двумя способами (строение или механизм). LLM-модель анализирует контекст предложения и выбирает правильное ударение автоматически.
Клонирование голоса и персонализированные модели
Одна из самых интересных возможностей — клонирование голоса. Озвучка текста нейросетью может воспроизвести ваш голос или голос известного актера. Для этого нужна всего одна-две минуты аудиозаписи, и модель научится копировать характерные черты: тембр, манеру говорить, особенности произношения.
Это используется для озвучки видео, когда нужно, чтобы персонаж говорил на другом языке, но звучал узнаваемо. Или для создания персональных голосовых ассистентов.
Эмоции, интонации и естественность голоса в 2026 году
Современные нейросети понимают эмоции текста. Если сценарий про любовь, озвучка ИИ звучит нежнее. Если про войну — жестче. Это не просто ускорение или замедление — это полная переработка интонационного рисунка.
Генерация речи нейросетью теперь поддерживает:
Результат: слушатель слышит не робота, а человека, который думает, дышит и переживает.
Понимание различий между двумя подходами поможет вам выбрать правильный сервис для своих задач. Некоторые платформы все еще используют классический TTS, другие уже полностью переехали на нейросетевой синтез.
Классический TTS: жесткие правила
Классический синтез речи основан на правилах лингвистики. Система анализирует текст по словарю, разбивает слова на фонемы и воспроизводит их по заранее установленным правилам. Если слово "слово" содержит букву "о", система прочитает её определённым образом — без вариаций.
Результат предсказуем, но звучит монотонно. Паузы расставляются механически (точка = длинная пауза, запятая = короткая). Ударения часто неправильные, потому что система не анализирует контекст — она просто применяет общие правила.
Озвучка текста нейросетью: понимание смысла
Нейросетевой синтез работает иначе. Модель не следует жестким правилам — она предсказывает, как должна звучать фраза, на основе примеров живой речи, на которых её обучили.
Озвучка нейросеть анализирует не буквы, а смысл. Если вы пишете: "Ты идешь в парк?", система понимает, что это вопрос, и автоматически поднимает интонацию в конце. Если: "Ты идешь в парк." — звучит как утверждение, интонация ровная.
Нейросеть может воспроизвести:
Сравнение в цифрах и примерах
| Критерий | Классический TTS | Нейросетевой синтез |
|---|---|---|
| Натуральность | 40–50% | 85–95% |
| Скорость обработки | Быстро (0.1 сек) | Медленнее (0.5–2 сек) |
| Качество редких слов | Плохое | Хорошее |
| Эмоциональность | Нет | Есть (в продвинутых моделях) |
| Стоимость | Дешевле | Дороже |
| Где используется | Старые IVR системы | YouTube, подкасты, современные боты |
Практический пример
Попробуем озвучить фразу: "Ты читаешь 'Война и мир'?"
Классический TTS прочитает: "Ты-чи-та-ешь. Война-и-мир." Ударения неправильные, интонация вопроса не слышна.
Озвучивание текста нейросетью озвучит: "Ты ЧИ-та-ешь 'Война́ и мир'?" — с правильными ударениями, вопросительной интонацией в конце и естественными паузами перед названием книги.
Когда еще используется классический TTS
Несмотря на преимущества нейросетей, классический TTS до сих пор применяется там, где важна минимальная задержка. Некоторые голосовые боты, старые навигаторы и системы безопасности используют классический синтез, потому что он работает за миллисекунды.
Но если вы создаете контент для YouTube, подкасты или аудиокниги, классический TTS уже не подходит. Слушатели сразу заметят неестественность. Озвучка ИИ на основе нейросетей — это стандарт качества в 2026 году.
LLM-based синтез речи — это прорыв 2024–2025 годов, который изменил понимание того, что может сделать нейросеть. Вместо отдельных моделей для анализа текста и генерации звука используется единая большая языковая модель, которая понимает контекст глубже.
Как работает LLM-based озвучка
Традиционный синтез речи нейросеть использовал двухэтапный процесс: сначала текст преобразуется в акустические параметры, потом эти параметры превращаются в звук. LLM-модель работает иначе — она анализирует весь контекст сразу и понимает, как должна звучать фраза в целом.
Озвучка ИИ на базе LLM позволяет модели:
Например, если текст: "Ну конечно, это лучший способ", — LLM поймет сарказм и озвучит фразу с иронией. Классический TTS или даже старые нейросети прочитали бы это буквально.
Управление эмоциональным окрасом
Главное преимущество озвучки нейросетью на базе LLM — вы можете управлять эмоциями. Вы не просто выбираете голос (мужской, женский, акцент), но и задаёте стиль:
Озвучивание текста нейросетью теперь звучит не как одно и то же для всех фраз, а как настоящее чтение актером, который понимает смысл того, что произносит.
Примеры в 2026 году
SberBank в конце 2025 года запустил свой LLM-based синтез речи под названием GigaChat. Система может озвучить деловой документ официально, а любовное письмо — нежно. Это привело к снижению стоимости озвучки на 30% при улучшении качества.
Озвучка видео нейросетью на платформах типа ElevenLabs теперь использует LLM-подход, позволяя синхронизировать не только звук с видео, но и эмоциональный окрас озвучки с визуальным рядом.
Скорость и качество
Нейросетевой синтез раньше занимал 0.5–2 секунды на одну фразу. LLM-модели работают на том же уровне, но результат качественнее. Для длинных текстов это означает, что вы получаете аудиофайл не медленнее, чем раньше, но звучит он в два раза лучше.
Будущее озвучки
В 2026 году LLM-based синтез становится стандартом. Компании, которые все еще используют классический TTS, начинают отставать. Озвучка ИИ на базе LLM позволит:
Главное — это уже не просто технология, а инструмент, который понимает язык так же хорошо, как человек.
Клонирование голоса — одна из самых впечатляющих возможностей современной озвучки нейросетью. Раньше это было прерогативой кино и мультипликации. Сегодня клонировать голос может каждый за несколько минут.
Как работает клонирование голоса
Процесс простой: вы загружаете аудиозапись длиной от одной до пяти минут. Это может быть ваш голос, голос актера или известного человека. Нейросеть анализирует записанные характеристики: тембр, высоту, манеру говорить, особенности произношения, даже дыхание и паузы.
На основе этого анализа модель создает "голосовой профиль" — уникальный набор параметров. Затем, когда вы загружаете новый текст, озвучивание текста нейросетью воспроизводит его в голосе, который был в исходной записи. Результат звучит как если бы этот человек сам прочитал новый текст.
Точность клонирования в 2026 году
Современные сервисы достигают 95–98% точности воспроизведения голоса. Это означает, что разница между оригинальной записью и клонированием почти неуловима для обычного слушателя. Даже специалист может ошибиться.
Озвучка ИИ на базе клонирования голоса позволяет:
Практические кейсы
YouTube-канал "Киноманы" использует озвучка текста нейросетью с клонированием голоса своего ведущего. Вместо того чтобы записывать каждый выпуск, они пишут сценарий, загружают в сервис, и озвучка звучит как сам ведущий. Это сэкономило им сотни часов студийной работы.
Видеоигры используют озвучивание текста нейросетью для дубляжа на разные языки. Персонаж американского актера озвучивается актером на русском, немецком, итальянском — и каждый звучит естественно на своём языке, но голос остаётся узнаваемым.
Персонализированные голосовые модели
Помимо клонирования чужого голоса, вы можете создать полностью персонализированный голос. Это голос, который существует только для вас или вашего бренда.
Озвучка нейросетью позволяет:
Крупные компании вроде Toyota и BMW создали собственные персонализированные голоса для своих голосовых ассистентов. Это укрепляет узнаваемость бренда.
Этические вопросы и защита
Озвучка видео нейросетью с клонированием голоса привела к проблемам. Мошенники могут использовать голос известного человека для создания поддельного видео (deepfake). Поэтому сервисы добавили защиту:
В России и многих странах клонирование чужого голоса без согласия незаконно. Озвучивание документов нейросетью или публичных фигур требует явного разрешения от правообладателя.
Стоимость и доступность
Клонирование голоса стоит дороже, чем выбор готового голоса из каталога. На ElevenLabs это стоит дополнительно 10–50 долларов в месяц. Но если вы создаёте много контента (YouTube-канал, подкасты, обучающие видео), это окупается за счет экономии времени.
Главное отличие озвучки в 2026 году от озвучки пять лет назад — это способность передать эмоции. Современная озвучка нейросетью звучит не просто понятно, а живо и убедительно.
Как нейросеть понимает эмоции
Озвучка ИИ анализирует текст на предмет эмоционального содержания. Если вы напишете: "Я так счастлив!", система поймет радость и озвучит фразу быстрее, с более высокой интонацией, с улыбкой в голосе. Если: "Мне очень грустно", — голос замедлится, станет глубже, появятся паузы.
Это не просто ускорение или замедление. Генерация речи нейросетью меняет буквально все: высоту голоса, громкость отдельных слов, длительность гласных звуков, интенсивность согласных. Модель воспроизводит то, как живой актер прочитал бы эту фразу с определённой эмоцией.
Управление интонациями и стилем
Продвинутые сервисы озвучки позволяют выбирать стиль речи:
Озвучивание текста нейросетью теперь предлагает не просто "прочитай это", а "прочитай это как опытный актер, который понимает смысл и передает нужные чувства".
Просодия: ритм и мелодика речи
Просодия — это ритмико-интонационная сторона речи, которая делает её живой. Это не отдельные звуки, а мелодия, которую создает голос при произношении фразы.
Озвучка текста ИИ воспроизводит:
Результат: слушатель не думает "это робот", а слышит человека.
Примеры трансформации
Одна и та же фраза "Люблю тебя" может быть озвучена:
Озвучка видео нейросетью использует эту возможность: если персонаж в видео плачет, озвучка будет грустной; если смеётся, озвучка будет весёлой.
Натуральность в реальных проектах
YouTube-канал с озвучкой на базе современной озвучки нейросетью практически неотличим от канала с живым диктором. Слушатель понимает эмоции, следит за ритмом, не отвлекается на неестественность.
Подкасты, озвученные озвучиванием текста нейросетью с правильными интонациями, удерживают внимание слушателя. Если озвучка монотонна, человек отключается в течение минуты.
Ограничения и реальность
Несмотря на прогресс, озвучка ИИ до сих пор иногда ошибается с контекстом. Если текст содержит иронию, которую трудно распознать, модель может прочитать его буквально. Если в тексте опечатка, озвучка может звучать странно.
Но в 90% случаев современная озвучка нейросетью звучит настолько естественно, что зритель не замечает, что это синтетический голос. И это уже достаточно хорошо для профессиональной работы.
Рынок озвучки нейросетью в 2026 году развивается стремительно. Существуют десятки платформ с разными подходами: одни ориентированы на качество, другие на доступность, третьи на специализацию. Выбор правильного сервиса зависит от ваших задач и бюджета.
На рынке есть международные гиганты (ElevenLabs, Google, Яндекс), российские сервисы (CyberVoice) и open-source решения. Каждый подход имеет смысл в определённых сценариях.
Далее разберем топовые сервисы, особенности озвучки на русском, специфику видео и выберем правильный инструмент для вашего проекта.
ElevenLabs — лидер рынка озвучки нейросетью в 2026 году. Платформа предлагает 500+ голосов на 29 языках, включая русский с обновлением конца 2025 года. Озвучка нейросетью здесь достигает наивысшего качества благодаря LLM-based синтезу.
Основные возможности:
Преимущества: Наивысшее качество озвучки на русском языке, профессиональные голоса, надежность сервиса, большой выбор стилей речи.
Минусы: Высокая цена (от 5 до 99 долларов в месяц), скудный бесплатный тариф (3000 символов в месяц), требует время для освоения всех функций.
Кто выбирает: Профессиональные YouTube-каналы, агентства, подкастеры и авторы, которые готовы платить за качество.
Voicemaker — идеальная платформа для тех, кто только начинает работать с озвучкой нейросетью. Озвучивание текста нейросетью здесь работает быстро и интuitively — результат за 5–10 секунд после загрузки сценария.
Основные возможности:
Преимущества: Щедрый бесплатный тариф (100 000 символов в месяц), огромный выбор голосов, простой интерфейс без лишних настроек, быстрая обработка, низкая цена на платных тарифах.
Минусы: Качество озвучки немного ниже, чем на ElevenLabs, видеозвуковая синхронизация недоступна на бесплатном плане, меньше опций для управления эмоциями.
Кто выбирает: Новички, блогеры, контент-мейкеры, которые хотят сэкономить и попробовать озвучку без риска.
CyberVoice — российский сервис, который специализируется именно на озвучке на русском языке. Озвучка нейросетью здесь звучит максимально естественно для русских слушателей: правильные диалекты, акценты, эмоциональные оттенки соответствуют русской речи.

Основные возможности:
Преимущества: Лучшее качество озвучки на русском языке в 2026 году, понимание русского контекста и фразеологии, цена ниже конкурентов (от 7 долларов в месяц), надежность на российском рынке.
Минусы: Ограниченный выбор голосов (50+), отсутствие клонирования голоса, нет встроенной озвучки видео, ориентирован в первую очередь на русский язык.
Кто выбирает: Русскоязычные контент-мейкеры, российские компании, авторы, для которых качество русской озвучки — приоритет.
PlayHT — специализированная платформа для озвучки видеоконтента. Озвучка видео нейросетью здесь работает с автоматической синхронизацией звука под видеоряд, что критично для YouTube и социальных сетей.
Основные возможности:
Преимущества: Встроенная озвучка видео без необходимости дополнительных инструментов, хорошая поддержка русского языка, клонирование голоса, надежная синхронизация, подходит для профессионального видеопроизводства.
Минусы: Высокая цена (от 19 долларов в месяц), интерфейс сложнее для новичков, требует время на освоение всех функций видеоредактора.
Кто выбирает: YouTube-канальщики, видеопродюсеры, компании, которым нужна озвучка видео с профессиональной синхронизацией.
Murf.ai — платформа для комплексного создания видеоконтента: озвучка + видеоаватары (говорящие головы). Озвучивание текста нейросетью здесь интегрируется с синтетическими персонажами, которые читают текст на экране.
Основные возможности:
Преимущества: Озвучка + видео аватар в одном месте (не нужны отдельные инструменты), встроенные шаблоны ускоряют создание, естественная синхронизация губ с озвучкой, подходит для обучающего контента и презентаций.
Минусы: Дороже конкурентов (от 19 долларов в месяц), может быть избыточным для простой озвучки только текста, требует подписку для доступа ко всем аватарам.
Кто выбирает: Создатели образовательного контента, компании для внутренних видео, авторы, которым нужны персонажи в видео.
Выбор сервиса озвучки зависит от вашей задачи, бюджета и требований к качеству. Вот матрица рекомендаций для разных сценариев использования.
Сценарий 1: YouTube-канал с еженедельными видео
Вам нужна озвучка видео нейросетью с профессиональным качеством и быстрой синхронизацией. Видео длиной 10–20 минут требуют стабильного сервиса.
Рекомендация: PlayHT или ElevenLabs. PlayHT лучше для озвучки видео, ElevenLabs лучше для клонирования собственного голоса. Бюджет: 19–50 долларов в месяц.
Альтернатива: Если снимаете на русском и бюджет ограничен — CyberVoice (от 7 долларов).
Сценарий 2: Подкаст на русском языке
Подкаст — это контент, где слушатель сосредоточен только на звуке. Озвучивание текста нейросетью должно звучать максимально естественно, с правильными интонациями и без артефактов.
Рекомендация: CyberVoice (лучший русский синтез) или ElevenLabs (если хотите клонировать свой голос). Для экономии: Voicemaker с тестированием разных голосов. Бюджет: 7–50 долларов в месяц.
Сценарий 3: Аудиокнига или длинный формат контента
Аудиокнига требует высокого качества озвучки, правильных ударений в редких словах, естественных пауз и дыхания. Озвучка текста ИИ должна звучать как настоящий актер.
Рекомендация: ElevenLabs или CyberVoice (оба хорошо работают с длинными текстами). Если бюджет ограничен и готовы тестировать: Voicemaker.in (100 000 символов бесплатно в месяц — достаточно для пробы).
Сценарий 4: Корпоративное видео и обучение
Корпоративный контент требует деловой озвучки: четкая дикция, нейтральный тон, синхронизация с видео. Озвучивание видео нейросетью должна быть быстрой и надежной.
Рекомендация: Murf.ai (встроенные шаблоны для обучающих видео, видеоаватары) или PlayHT (если нужна только озвучка без аватара). Бюджет: 19–50 долларов в месяц.
Сценарий 5: Реклама и маркетинг-видео
Рекламное видео требует энергичной, убеждающей озвучки. Озвучка ИИ должна передавать эмоции и привлекать внимание.
Рекомендация: ElevenLabs (управление эмоциями, клонирование) или Murf.ai (встроенные шаблоны для рекламы). Для быстрого прототипирования: Voicemaker. Бюджет: 5–50 долларов в месяц.
Сценарий 6: Озвучка TikTok и Reels (короткие видео)
Короткие видео требуют быстрой озвучки и энергичного тона. Озвучивание текста нейросетью должно быть мгновенным.
Рекомендация: Voicemaker.in (быстро, бесплатный тариф щедрый) или встроенные голоса TikTok/Instagram. Если хотите качество: ElevenLabs с быстрой обработкой. Бюджет: бесплатно или 5–20 долларов в месяц.
Сценарий 7: Многоязычный дубляж видео
Нужно озвучить видео на разные языки, сохраняя узнаваемость голоса оригинального персонажа.
Рекомендация: ElevenLabs (клонирование голоса + дубляж на 29 языков) или PlayHT (озвучка видео с синхронизацией на разные языки). Бюджет: 20–99 долларов в месяц.
Сценарий 8: Бюджет минимальный, но нужна озвучка
Нет денег на подписку, но нужна озвучка нейросетью для пробы.
Рекомендация: Voicemaker.in (100 000 символов в месяц бесплатно — это 20–30 видео среднего размера) или Silero Models (полностью бесплатно, но требует технических навыков). Бюджет: 0 долларов.
Озвучка текста — самый простой способ начать работу с озвучкой нейросетью. Процесс занимает несколько минут: подготовить текст, выбрать сервис, выбрать голос, нажать кнопку "Генерировать".
Но есть нюансы, которые влияют на качество результата. Текст нужно правильно подготовить, выбрать подходящий голос и знать, какие ошибки часто совершают новички.
В этом блоке разберемся, как правильно озвучить текст с первой попытки, избежать распространенных ошибок и получить профессиональный результат.
Основные этапы:
Подготовка текста (структура, пунктуация, проверка ошибок). Выбор сервиса озвучки и регистрация. Загрузка текста и выбор голоса. Настройка параметров (скорость, тон, эмоции). Генерация и экспорт готового аудиофайла.
Каждый из этих этапов важен для качества озвучивания текста нейросетью. Ошибка на одном этапе может испортить весь результат.
Качество озвучки нейросетью зависит на 50% от качества исходного текста. Если текст содержит ошибки, странную пунктуацию или непонятные сокращения, озвучка будет звучать странно. Нейросеть озвучивает ровно то, что написано — без фильтра и интерпретации.
Правила подготовки текста
Проверка ошибок и опечаток. Перед загрузкой текста в сервис озвучки, тщательно проверьте его на ошибки. Опечатка вроде "исползовать" вместо "использовать" нейросеть озвучит именно как "исползовать" — со странным произношением. Озвучивание текста нейросетью не исправляет ошибки автоматически.
Правильная пунктуация. Нейросеть анализирует пунктуацию для расстановки пауз и интонаций:
Если в тексте нет пунктуации или она расставлена неправильно, озвучка текста ИИ звучит монотонно и непонятно.
Разбивка на фрагменты. Для длинных текстов (более 5000 символов) рекомендуется разбить на части. Это помогает:
Разбивайте по логическим блокам: параграфы, главы, смысловые куски. Не режьте середину предложения.
Обработка специальных элементов
Числа и даты. Как нейросеть озвучивает число "2025"? Некоторые системы читают "две тысячи двадцать пять", другие "двадцать двадцать пять". Проверьте в сервисе, как он озвучивает числа, и при необходимости напишите числа словами: "две тысячи двадцать пять" вместо "2025".
Сокращения и аббревиатуры. "ООО", "COVID-19", "CEO" — как их озвучить? Опять же, зависит от сервиса. Для безопасности пишите расшифровку: "Общество с ограниченной ответственностью" вместо "ООО".
Иностранные слова и имена. Если в тексте много английских слов или имён иностранцев, озвучивание текста нейросетью может озвучить их с русским акцентом. Для нужного произношения добавляйте подсказку в скобках: "iOS (айос)".
Знаки и символы. Точки, дефисы, кавычки — нейросеть их пропускает. Это нормально: "ООО "Компания"" озвучится как "Компания", без упоминания кавычек.
Структура текста для озвучки видео
Если вы озвучиваете текст под видео, добавьте информацию о синхронизации:
Например:
[0–5 сек] Добро пожаловать на наш канал! [5–8 сек] Сегодня мы поговорим о озвучке. [8–15 сек] Это не так сложно, как кажется.
Такая разметка помогает сервису синхронизировать озвучку с видео.
Проверка перед озвучкой
Перед загрузкой текста в сервис:
Прочитайте текст вслух — услышите ошибки и странности. Проверьте пунктуацию — особенно на вопросы и восклицания. Убедитесь, что числа и имена озвучены правильно. Протестируйте на коротком отрывке (если сервис это позволяет).
Озвучка нейросетью очень чувствительна к входным данным. Потратив 5 минут на подготовку текста, вы сэкономите 30 минут на корректировке результата.
Озвучка текста в онлайн-сервисе занимает 5–10 минут. Вот пошаговый процесс на примере популярных платформ (Voicemaker, ElevenLabs, CyberVoice).
Шаг 1: Регистрация и вход в сервис
Откройте сайт выбранного сервиса озвучки. Создайте аккаунт (email + пароль) или войдите через Google. Большинство сервисов предлагают бесплатный тариф с лимитом символов в месяц. Озвучивание текста нейросетью обычно доступно сразу после регистрации.
Шаг 2: Загрузка или вставка текста
В главное окно сервиса вставьте ваш текст. Есть несколько способов:
Озвучка нейросетью показывает количество символов и оставшийся лимит на вашем тарифе. Если текст слишком длинный, разбейте на части.
Шаг 3: Выбор голоса
Сервис предложит список доступных голосов. Вы можете выбрать по:
Нажмите на голос, чтобы услышать образец озвучки (обычно фраза "Привет, это голос [имя]"). Озвучивание текста нейросетью звучит по-разному в зависимости от выбранного голоса — выберите тот, который подходит под ваш контент.
Рекомендация: прослушайте 2–3 голоса перед выбором. То, что звучит хорошо на образце, может звучать странно на вашем тексте.
Шаг 4: Настройка параметров озвучки
Большинство сервисов позволяют настроить:
Скорость речи (0.5x до 2x): 0.9–1.1x — оптимально для комфортного восприятия. Медленнее для аудиокниг и обучения, быстрее для рекламы и коротких видео.
Тон и эмоции (если поддерживается): радостный, грустный, спокойный, энергичный. Озвучка текста ИИ меняет интонацию в зависимости от выбранного тона.
Громкость и нормализация: оставьте по умолчанию, если сервис советует.
На ElevenLabs и некоторых других можно настроить "Stability" (стабильность) и "Clarity" (четкость) — оставьте стандартные значения для начала.
Шаг 5: Предпросмотр (если доступен)
Перед окончательной генерацией нажмите "Preview" или "Прослушать". Озвучка нейросетью проиграет первые 10–20 секунд текста. Проверьте:
Если не нравится — вернитесь на шаг 3 и выберите другой голос.
Шаг 6: Генерация озвучки
Нажмите кнопку "Generate" (Генерировать) или "Озвучить". Сервис обработает текст. Время ожидания:
Во время обработки видите прогресс (%), индикатор загрузки или просто ждете.
Шаг 7: Прослушивание результата
После генерации сервис проиграет озвученный файл. Слушайте внимательно:
Если результат хороший — переходите к шагу 8. Если нет — можно отредактировать отдельные фрагменты или генерировать заново с другим голосом.
Шаг 8: Экспорт готового файла
Нажмите "Download" (Скачать) или "Экспортировать". Выберите формат:
Файл скачивается на ваш компьютер. Озвучка текста ИИ готова к использованию.
Советы и экономия лимитов
Даже опытные пользователи делают ошибки при озвучке нейросетью. Знание этих ошибок поможет вам избежать переделки и сэкономить время.
Ошибка 1: Текст с ошибками и опечатками
Нейросеть озвучивает ровно то, что написано. Если вы загрузили текст с опечатками, озвучка нейросетью озвучит их как есть.
Пример: "исползовать" вместо "использовать" — нейросеть озвучит странно.
Решение: Перед загрузкой проверьте текст на ошибки. Используйте встроенную проверку орфографии (Ctrl+F7 в Word, или онлайн-сервисы вроде Grammarly).
Ошибка 2: Отсутствие или неправильная пунктуация
Пунктуация — это инструкция для нейросети, как озвучивать текст. Без пунктуации озвучивание текста нейросетью звучит монотонно.
Пример:
Решение: Добавьте правильную пунктуацию перед озвучкой. Точки в конце предложений, запятые при перечислении, восклицательные знаки для эмоций.
Ошибка 3: Странное озвучивание имён и редких слов
Нейросеть может неправильно озвучить имя собственное или редкое слово.
Пример: "Дмитрий" может быть озвучена с неправильным ударением, иностранное имя "Жюль" озвучится с русским акцентом.
Решение: Для редких и иностранных слов напишите подсказку: "Жюль (жюль, французское имя)" или используйте функцию редактирования отдельных слов, если сервис её поддерживает.
Ошибка 4: Неправильное озвучивание чисел и дат
Нейросеть не всегда понимает, нужно ли озвучить число цифрой или словами.
Пример: "2025" может озвучиться как "две тысячи двадцать пять" или как "двадцать двадцать пять" — зависит от системы.
Решение: Пишите числа словами для важных моментов: "две тысячи двадцать пять" вместо "2025". Для дат: "первое января две тысячи двадцать шестого" вместо "01.01.2026".
Ошибка 5: Выбор неправильного голоса для контента
Женский голос для мужского персонажа, энергичный голос для грустного текста — озвучка текста ИИ будет звучать несогласованно.
Пример: Озвучиваете мужской текст (от автора-мужчины) женским голосом — звучит странно.
Решение: Выберите голос, который подходит под ваш контент. Мужской голос для мужского персонажа, спокойный для аудиокниги, энергичный для рекламы.
Ошибка 6: Игнорирование параметров скорости речи
Используете стандартную скорость (1x) для всех контентов — получается либо слишком быстро, либо слишком медленно.
Решение: Настройте скорость под контент:
Ошибка 7: Озвучка очень длинного текста за один раз
Если озвучить 10 000+ символов за один раз, нейросеть может допустить ошибки в синтезе. Паузы будут неправильные, интонация сбившаяся.
Решение: Разбейте длинный текст на куски (по 2000–5000 символов). Озвучьте каждый кусок отдельно, потом склейте аудиофайлы в аудиоредакторе (Audacity, Adobe Audition).
Ошибка 8: Не проверить результат перед скачиванием
Нажали "Озвучить", не слушали предпросмотр, сразу скачали — получился мусор.
Решение: Всегда слушайте предпросмотр или первые 10 секунд озвучки перед финальной генерацией. Если что-то не так, вернитесь к выбору голоса или параметров.
Ошибка 9: Использование одного голоса для разных персонажей
Если в вашем тексте разные люди говорят, а вы озвучиваете одним голосом, получается скучно.
Решение: Озвучьте реплики разных персонажей разными голосами. Разбейте текст на части, озвучьте каждую своим голосом, потом склейте.
Ошибка 10: Забыть сохранить исходный текст
Озвучили текст, получился результат — но потом нужно озвучить другой вариант, а оригинальный уже потёрли.
Решение: Всегда сохраняйте исходный текст в отдельную папку. Озвучку сохраняйте с названием голоса и скорости ("озвучка_женский_1.0x.mp3"). Это поможет не переделывать заново.
Озвучка длинных текстов, деловых документов и сценариев требует особого подхода. Здесь работают другие правила, чем при озвучке короткого материала.
Озвучка длинных текстов (10 000+ символов)
Когда текст очень длинный (аудиокнига, курс, большая статья), озвучка нейросетью может потерять качество к концу.
Проблемы:
Решение: Разбейте длинный текст на блоки по 3000–5000 символов. Озвучьте каждый блок отдельно с одним голосом и параметрами. Потом склейте аудиофайлы в аудиоредакторе (Audacity, Adobe Audition, или онлайн-сервис Audio Joiner).
Озвучка деловых документов
Деловой документ (приказ, служебная записка, инструкция) требует официального тона и четкой дикции. Озвучивание текста нейросетью должна звучать как профессиональный диктор, без эмоций.
Рекомендации:
Пример: Служебная записка озвучивается спокойно, без эмоций, с паузами после точек и запятых. Озвучка текста ИИ должна звучать как человек, читающий приказ на совещании.
Озвучка сценариев для видео
Сценарий для видео — это текст, который будет озвучен под визуальный контент. Здесь нужна синхронизация не только со смыслом, но и с временем видео.
Подготовка сценария:
Разделите сценарий на сцены или последовательности по времени. Укажите временные коды рядом с текстом (где озвучка должна начаться и закончиться). Отметьте, где нужны паузы для визуальных переходов.
Пример структуры:
[0–5 сек] Добро пожаловать на наш канал YouTube! [Пауза 2 сек для заставки] [5–12 сек] Сегодня мы разберемся, как озвучить видео за 5 минут. [Пауза 1 сек] [12–20 сек] Это просто, если знать несколько хитростей.
Озвучка нейросетью с такой разметкой легче синхронизируется с видео. Если вы используете платформу типа PlayHT или Murf.ai, она автоматически синхронизирует озвучку по временным кодам.
Работа с диалогами в сценариях
Если в сценарии есть диалоги (разговор двух или более персонажей), озвучьте каждого отдельным голосом.
Процесс:
Разделите диалог: реплики персонажа A, реплики персонажа B. Озвучьте реплики персонажа A одним голосом (например, мужским). Озвучьте реплики персонажа B другим голосом (например, женским). Склейте в правильном порядке в аудиоредакторе.
Озвучивание текста нейросетью для разных персонажей делает контент более живым и интересным.
Оптимизация озвучки документов для разных форматов
Для веб-версии: озвучьте документ со скоростью 1.0–1.1x, сохраните в MP3. Размер файла меньше, быстрее загружается на сайт.
Для аудиокниги: озвучьте со скоростью 0.85–0.95x, сохраните в высоком качестве (320 kbps MP3 или WAV). Слушатель должен комфортно воспринимать информацию.
Для подкаста: озвучьте со скоростью 0.95–1.05x, добавьте вводящую музыку и переходы. Озвучка текста ИИ должна звучать как естественный разговор, а не чтение.
Сохранение озвученных материалов
После озвучки сохраняйте:
Исходный текст (для редактирования и переозвучки). Озвученный файл (MP3 или WAV). Информацию о параметрах озвучки (голос, скорость, эмоции) — для консистентности в будущем.
Если у вас есть несколько документов, озвученных одним голосом, это создаёт единый бренд-звук. Слушатель привыкает к этому голосу и узнаёт ваш контент.
Озвучка видео сложнее, чем озвучка текста. Здесь нужна синхронизация звука с видеорядом, учет визуальных элементов и правильная расстановка пауз по времени.
Отличие от озвучки текста: озвучка видео нейросетью должна не только звучать хорошо, но и совпадать с видео по времени. Если озвучка начинается раньше или позже, чем нужно, результат выглядит странно.
Основные этапы озвучки видео:
Подготовка материала — сценарий, структура видео, временные коды. Загрузка видео в сервис — выбор платформы. Озвучка и синхронизация — генерация звука с автоматической привязкой к видео. Корректировка — ручная подгонка озвучки, если нужно. Экспорт — скачивание готового видео с озвучкой.
Озвучивание видео нейросетью занимает 15–30 минут для видео среднего размера (5–10 минут). Это намного быстрее, чем записывать свой голос в студии.
В следующих разделах разберемся в каждом этапе подробно, научимся выбирать сервис под вашу задачу и избегать типичных ошибок при озвучке видео.
Качество озвучки видео нейросетью зависит от подготовки исходного материала. Если видео хорошо структурировано, с четким сценарием и временными кодами, озвучка синхронизируется автоматически и звучит профессионально.
Подготовка сценария
Сценарий — это текст, который будет озвучен. Он должен быть:
Структурирован: разбит на части, соответствующие сценам видео. Синхронизирован: каждая часть текста связана с конкретным моментом видео. Редактирован: без ошибок, с правильной пунктуацией.
Напишите сценарий в текстовом редакторе (Word, Google Docs) или прямо в сервисе озвучки видео.
Пример структуры сценария:
[0–3 сек] Добро пожаловать на канал о нейросетях! [3–8 сек] Сегодня мы разберемся, как озвучить видео за 10 минут. [Пауза 2 сек – показываем заставку] [8–15 сек] Это просто, если знать несколько секретов. [15–20 сек] Первый секрет – выбрать правильный сервис.
Временные коды (в квадратных скобках) показывают, в какой момент видео должна начинаться озвучка. Это критично для синхронизации.
Анализ видео и определение временных кодов
Перед озвучкой смотрите видео и отмечайте:
Озвучивание видео нейросетью работает лучше, если вы максимально точно указали, где должна быть озвучка. Сервис будет синхронизировать звук именно по этим кодам.
Инструменты для определения временных кодов:
Работа с аудиодорожками в видеоредакторе
Если вы готовите видео в редакторе (Premiere, DaVinci Resolve, CapCut), подготовьте "дорожку для озвучки":
Откройте видеопроект в редакторе. Добавьте новую аудиодорожку (обычно "Audio Track"). Импортируйте озвученный аудиофайл на эту дорожку. Синхронизируйте звук с видео, перетащив его на нужный временной код.
Преимущество: если озвучка не совпадает идеально, вы можете сдвинуть звук на несколько кадров без переделки.
Субтитры для синхронизации
Если видео уже содержит субтитры (SRT-файл), это поможет сервису озвучки автоматически синхронизировать звук.
Сервисы типа PlayHT и ElevenLabs могут:
Результат: озвучка видео ИИ начнется ровно в момент, когда появляется субтитр, и закончится перед следующим субтитром.
Разметка видео для разных сценариев
Для YouTube-видео (10–20 минут):
Для TikTok (15–60 секунд):
Для рекламного видео:
Проверка материала перед озвучкой
Перед загрузкой видео в сервис озвучки:
Смотрите видео целиком — убедитесь, что оно готово к озвучке. Проверьте сценарий — нет ошибок, пунктуация правильная. Убедитесь в синхронизации — каждая часть сценария соответствует моменту в видео. Тестируйте озвучку на коротком отрывке — если сервис позволяет, озвучьте первые 30 секунд для проверки.
Эта подготовка займет 15–30 минут, но сэкономит вам часы на корректировке результата. Озвучка видео нейросетью работает эффективнее, когда исходный материал хорошо подготовлен.
Озвучка видео в современных сервисах работает по определённому алгоритму. Понимание этого процесса помогает выбрать правильный сервис и использовать его эффективнее.
Как работает озвучка видео в сервисах TTS
Озвучка видео нейросетью в платформах типа PlayHT, ElevenLabs и Murf.ai происходит в несколько этапов:
Этап 1: Загрузка видео и анализ контента
Вы загружаете видеофайл (MP4, WebM, MOV). Сервис анализирует видео:
Этап 2: Синтез озвучки
Система генерирует аудиодорожку из текста. Озвучивание видео нейросетью происходит с учётом временных кодов:
Алгоритм автоматически подстраивает скорость речи, чтобы озвучка точно совпала по времени с видео.
Этап 3: Синхронизация и обработка
После генерации озвучки система:
Этап 4: Экспорт видео
Готовое видео с озвученной дорожкой экспортируется в выбранный формат (MP4, WebM). Озвучка встроена в видеофайл — видео готово к публикации.
Алгоритм дубляжа: озвучка на разные языки
Дубляж — это озвучка видео на другом языке с сохранением узнаваемости оригинального голоса.
Процесс дубляжа:
Извлечение текста: система извлекает озвучку из оригинального видео (или использует предоставленный сценарий). Перевод: текст автоматически переводится на целевой язык (например, с английского на русский). Некоторые сервисы позволяют загрузить готовый перевод вручную. Клонирование голоса: если вы загрузили образец оригинального голоса, система создает его копию для целевого языка. Озвучивание видео нейросетью звучит как оригинальный персонаж, но говорит на другом языке. Синхронизация: озвучка на новом языке синхронизируется с видео. Проблема: разные языки требуют разного количества времени для произношения. "Hello" (1 слог) требует меньше времени, чем "Привет" (2 слога). Алгоритм сокращает или расширяет озвучку, чтобы она совпадала по времени. Экспорт: видео с новой озвучкой на новом языке готово.
Проблема синхронизации при дубляже
Основная сложность: язык A требует 10 секунд, язык B требует 12 секунд для того же смысла.
Решения:
Хорошие сервисы (ElevenLabs, PlayHT) справляются с этим автоматически. Озвучка видео нейросетью остается естественной, несмотря на требования синхронизации.
Особенности алгоритма для разных форматов
YouTube (длинные видео, 10–20 минут):
Алгоритм разбивает видео на сегменты (по 1–2 минуте), озвучивает каждый отдельно, потом склеивает. Это помогает:
TikTok (15–60 секунд):
Алгоритм работает иначе: видео обрабатывается целиком за раз, но с акцентом на скорость. Озвучивание видео нейросетью должна быть готова за 10–20 секунд, а не за минуту.
Реклама (30 секунд, строгие требования к синхронизации):
Алгоритм работает на микроуровне: каждое слово озвучки привязано к конкретному кадру видео. Это требует максимальной точности.
Управление параметрами озвучки
При загрузке видео в сервис вы выбираете:
Сервис использует эти параметры в алгоритме. Озвучка видео ИИ генерируется с учётом всех этих настроек.
Что происходит за кулисами
Когда вы нажимаете "Озвучить видео":
Сервис отправляет видео и сценарий на облачные серверы. Серверы разбивают задачу на подзадачи (синтез, синхронизация, обработка). Нейросети работают параллельно, синтезируя озвучку. Система проверяет качество (нет ли артефактов, правильна ли синхронизация). Видео с озвучкой собирается и готовится к экспорту. Вы получаете уведомление, что видео готово.
Все это занимает 30 секунд – 5 минут в зависимости от длины видео и нагрузки на серверы.
Синхронизация — самая критичная часть озвучки видео. Если озвучка не совпадает с видео по времени, зритель это заметит сразу. Озвучка видео нейросетью должна начинаться ровно в нужный момент и заканчиваться вместе с видеорядом.
Автоматическая синхронизация
Современные сервисы (PlayHT, ElevenLabs, Murf.ai) синхронизируют озвучку автоматически.
Как это работает:
Вы загружаете видео и сценарий с временными кодами (0–5 сек, 5–10 сек и т.д.). Система анализирует временные коды и генерирует озвучку нужной длительности для каждого фрагмента. Если текст требует 7 секунд, но в окне только 5 секунд, алгоритм замедляет речь. Если текст требует 3 секунды, но окно 5 секунд, добавляются естественные паузы.
Озвучивание видео нейросетью подстраивается под видео автоматически.
Преимущества автоматической синхронизации:
Минусы:
Использование субтитров для синхронизации
Если видео содержит SRT-файл (субтитры), сервис может использовать его для идеальной синхронизации.
Процесс:
Загрузите видео + SRT-файл с субтитрами. Система извлекает текст и временные коды из субтитров. Озвучка видео ИИ генерируется ровно на время каждого субтитра.
Результат: озвучка начинается с появлением текста на экране и заканчивается перед следующим субтитром.
Пример SRT:
1 00:00:00,000 --> 00:00:05,000 Добро пожаловать на канал!
2 00:00:05,000 --> 00:00:12,000 Сегодня мы разберемся с озвучкой видео.
Сервис озвучит первую фразу за 5 секунд, вторую за 7 секунд. Озвучивание видео нейросетью будет идеально синхронизировано.
Ручная синхронизация в видеоредакторе
Если автоматическая синхронизация не подошла, можно отредактировать озвучку в видеоредакторе.
Процесс:
Озвучьте видео в сервисе (например, PlayHT). Скачайте готовое видео или только аудиодорожку. Откройте видеопроект в редакторе (Premiere, DaVinci Resolve, CapCut). Импортируйте озвученную аудиодорожку. Слушайте видео и смотрите, где озвучка не совпадает. Сдвигайте аудиодорожку влево (раньше) или вправо (позже) на нужное количество кадров.
В Premiere:
Озвучка видео нейросетью становится синхронизированной после этого.
Работа с диалогами и перекрытиями
Если в видео два персонажа говорят поочередно, может быть задержка между фразами.
Проблема: озвучка первого персонажа заканчивается, но видео показывает паузу в 1 секунду перед репликой второго. Озвучка второго должна начинаться ровно в этот момент.
Решение:
Проверка синхронизации
Перед публикацией видео проверьте синхронизацию на разных устройствах:
На компьютере: смотрите видео полностью, ищите рассинхрон. На мобильном: озвучка может работать по-другому на разных разрешениях. На разных браузерах: некоторые браузеры обрабатывают видео медленнее. На YouTube/TikTok: после загрузки проверьте еще раз, может быть небольшой lag при обработке.
Если озвучка не совпадает на YouTube, это может быть из-за обработки платформой. Обычно синхронизация восстанавливается через несколько часов.
Синхронизация для разных форматов
YouTube (10–20 минут): озвучка видео ИИ должна быть идеально синхронизирована. Зритель заметит рассинхрон даже в 0.5 секунды. Используйте автоматическую синхронизацию + проверьте в редакторе.
TikTok (15–60 секунд): коротких видео рассинхрон заметен сильнее. Озвучка должна совпадать до кадра. Используйте встроенные инструменты TikTok или генерируйте озвучку специально под видео.
Реклама (30 секунд): максимальная требовательность к синхронизации. Каждое слово озвучки должно совпадать с визуальным элементом. Используйте временные коды на миллисекунды, проверьте несколько раз.
Инструменты для синхронизации
Озвучка для разных платформ требует разного подхода. Озвучка видео нейросетью на YouTube звучит иначе, чем на TikTok или в рекламе. Каждый формат имеет свои требования к качеству, темпу, тону и длительности.
Озвучка для YouTube
YouTube — это платформа длинного контента. Видео длятся от 5 до 20+ минут. Зритель сосредоточен на содержании, поэтому озвучка должна быть максимально профессиональной.
Требования:
Особенности:
Кейс: YouTube-канал про технику озвучивает видео голосом мужского диктора, спокойный тон, скорость 1.0x. Зритель слушает 15 минут, не отвлекаясь, потому что озвучка звучит естественно.
Озвучка для TikTok
TikTok и Reels — это короткие видео (15–60 секунд). Зритель скроллит быстро, поэтому озвучка должна привлечь внимание сразу.
Требования:
Особенности:
Кейс: TikTok-видео про лайфхак озвучивается женским голосом, энергично, скорость 1.2x. За 30 секунд дикторша успевает рассказать суть и завершить видео воодушевляющей фразой.
Озвучка для рекламы
Реклама — это самый требовательный формат. Каждое слово озвучки должно совпадать с визуальным элементом и вызывать эмоцию.
Требования:
Особенности:
Кейс: Реклама смартфона озвучивается мужским голосом, убеждающий тон. "Камера в 200 мегапикселей" озвучивается ровно, когда камера показана крупно на экране. Темп: 1.0x, четкое произношение, ударения на важные слова.
Озвучка для YouTube
YouTube — промежуточный формат между YouTube и TikTok (до 60 секунд). Требования похожи на TikTok, но с большей требовательностью к качеству озвучки.
Требования:
Практические советы
Главный вопрос новичков: "Будет ли озвучка звучать как робот?" Ответ — нет, если вы знаете несколько секретов. Озвучка нейросетью в 2026 году звучит настолько естественно, что слушатели не отличают её от живого голоса. Но это требует правильного выбора голоса, понимания эмоций и корректной подготовки текста.
Что делает голос «человеческим»: тембр, скорость, паузы, интонация
Живой голос — это не просто звуки. Это сочетание нескольких элементов. Озвучивание текста нейросетью становится живым, когда эти элементы работают правильно.
Тембр — это характер голоса (грубый, мягкий, звонкий). Выбирайте голос, который подходит под контент. Для обучающего видео — спокойный, для рекламы — энергичный. Каждый голос в сервисе имеет разный тембр: протестируйте несколько.
Скорость речи влияет на восприятие. 0.9–1.0x звучит естественнее, чем 1.5x (слишком быстро, как ускоренное видео). Озвучка текста ИИ при оптимальной скорости звучит как человек, который говорит осознанно, а не торопится.
Паузы — это дыхание между предложениями. Нейросеть добавляет паузы после точек, запятых и многоточий. Правильная пунктуация в исходном тексте = естественные паузы в озвучке. Без пауз озвучка звучит монотонно и утомляет.
Интонация — это мелодия речи. Вопрос должен звучать с восходящей интонацией ("Вы готовы?"), утверждение — с нисходящей ("Я готов."). LLM-based модели понимают пунктуацию и автоматически подстраивают интонацию.
Работа с эмоциями: радостный, нейтральный, серьезный, рекламный тон
Продвинутые сервисы (ElevenLabs, CyberVoice) позволяют управлять эмоциями озвучки. Один текст может звучать по-разному:
Радостный тон: голос выше, темп быстрее, паузы короче. "Это отличная новость!" звучит с искренней радостью. Используйте для позитивного контента, рекламы успеха, поздравлений.
Нейтральный тон: объективный, без эмоций. Для новостей, инструкций, деловой информации. Слушатель сосредоточен на информации, а не на эмоциях диктора.
Серьезный тон: голос ниже, темп медленнее, паузы длинные. "Это требует внимания" звучит серьёзно. Для аналитики, документов, важных сообщений.
Рекламный тон: убеждающий, с эмоциональными вспышками. "Это лучшее решение на рынке!" звучит как рекомендация от друга. Для продаж и маркетинга.
Озвучка видео нейросетью с правильным тоном вызывает нужную эмоцию у зрителя. Неправильный тон — и весь контент теряет эффект.
Настройки, которые чаще всего портят озвучку (и как их исправить)
Ошибка 1: Слишком высокая скорость. Слушатель не успевает воспринимать информацию. Решение: используйте 0.95–1.1x для большинства контента.
Ошибка 2: Неправильная эмоция. Серьезный текст озвучивается радостно, или наоборот. Решение: выберите эмоцию, которая соответствует содержанию.
Ошибка 3: Слишком много модификаций. Чем больше вы крутите ползунки (стабильность, громкость, эффекты), тем менее естественной становится озвучка. Решение: используйте стандартные настройки, только если результат вас не устраивает.
Ошибка 4: Выбор голоса, не подходящего под контент. Женский голос для научного доклада, детский голос для серьезной темы. Решение: протестируйте голос на коротком отрывке перед полной озвучкой.
Как подготовить текст, чтобы нейросеть звучала максимально живо
Пунктуация — королева натуральности. Нейросеть анализирует пунктуацию для интонации. Вопросительный знак = восходящая интонация, восклицательный = энергия. Без пунктуации озвучка звучит монотонно.
Короткие предложения. "Я пошел в магазин. Купил хлеб. Вернулся домой." звучит живее, чем одно длинное предложение. Каждая точка = пауза для дыхания.
Избегайте аббревиатур и сокращений. "ООО" нейросеть озвучит странно. Пишите "Общество с ограниченной ответственностью" или хотя бы "ООО (о-о-о)".
Проверьте текст на ошибки. Опечатка "исползовать" озвучится как ошибка. Озвучивание текста нейросетью не исправляет текст автоматически.
Добавьте эмоциональные слова. "Это хорошо" vs "Это просто потрясающе!" Второй вариант озвучится с большей энергией, потому что нейросеть видит восклицательный знак и слово "потрясающе".
Результат: когда текст подготовлен правильно, озвучка нейросетью звучит как профессиональный диктор, который понимает смысл и передает нужные эмоции. Зритель забывает, что это синтетический голос, и сосредоточивается на содержании.
Озвучка нейросетью — это мощный инструмент, но он поднимает вопросы о безопасности, правах и этике. Перед использованием сервиса важно понять, что происходит с вашими данными и контентом.
Кто владеет озвученным голосом и аудиофайлом
Когда вы генерируете озвучку, кто её собственник?
Хорошая новость: большинство сервисов (ElevenLabs, PlayHT, Voicemaker) дают вам полные права на озвученный аудиофайл. Вы можете публиковать его на YouTube, использовать в коммерческих целях, продавать контент — без ограничений.
Исключение: если вы используете голос из каталога сервиса (предустановленные голоса), вы не владеете самим голосом, только озвученным файлом. Сервис остаётся владельцем голоса, вы можете использовать озвучку, но не продавать саму модель голоса.
При клонировании голоса: если вы загружаете свой голос, то вы владеете клонированной моделью. Сервис не может использовать вашу модель для других целей без согласия.
Озвучивание видео нейросетью — это ваша собственность. Вы можете делать с озвученным видео всё, что захотите.
Конфиденциальность: куда уходит загружаемый текст и видео
Когда вы загружаете текст или видео в сервис озвучки, он обрабатывается на облачных серверах компании.
Что происходит с данными:
Риски:
Как защитить данные:
Авторские права и использование озвучки на YouTube и в рекламе
На YouTube: озвучка, созданная нейросетью, не нарушает авторские права YouTube. Вы можете монетизировать видео с озвучкой озвучка видео ИИ. YouTube не будет блокировать видео за использование синтетического голоса.
Важно: если вы озвучиваете содержимое, защищённое авторским правом (чужой текст, чужие идеи), озвучка не делает его оригинальным. Авторские права распространяются на содержание, а не на форму озвучки.
В рекламе: озвучка нейросетью полностью ваша собственность. Вы можете использовать её в рекламных кампаниях, продавать контент с озвучкой. Нет лицензионных ограничений (если вы используете голоса из каталога, а не клонировали чужой голос).
Если вы клонировали голос знаменитости: это может нарушить его авторские права на его голос. В некоторых странах (Калифорния, Франция) есть законы о защите голоса публичных фигур. Озвучивание видео нейросетью с голосом знаменитости без его согласия может привести к судебным действиям.
Этические вопросы клонирования голоса и deepfake‑риски
Клонирование голоса — это когда вы загружаете аудиозапись человека, и нейросеть создает модель, которая воспроизводит его голос на новый текст. Это поднимает этические вопросы.
Легальное использование:
Проблематичное использование:
Deepfake‑риски: озвучка видео нейросетью в сочетании с видео поддельного персонажа создает deepfake. Это может быть использовано для мошенничества, фальсификации доказательств, распространения дезинформации.
Регуляция: в России, ЕС, США появляются законы против deepfake. Создание поддельных видео известных людей может быть незаконно. Некоторые сервисы требуют согласие при клонировании голосов публичных фигур.
Что делают сервисы:
Рекомендации для пользователей:
Итог: озвучка нейросетью безопасна и легальна, если вы используете её правильно. Риски возникают при нарушении авторских прав, конфиденциальности и этики. Выбирайте репутационные сервисы, проверяйте политику конфиденциальности и используйте инструмент ответственно.
Рынок озвучки нейросетью развивается стремительно. Каждые несколько месяцев появляются новые возможности, которые делают синтетический голос всё более неотличимым от живого. Понимание трендов помогает выбрать инструмент, который не устареет через год.
LLM‑based синтез речи: что изменится в ближайшие годы
LLM-based синтез (на основе больших языковых моделей) — это прорыв 2024–2025 годов. Вместо отдельных систем анализа текста и синтеза звука используется единая модель, которая понимает глубокий контекст.
Что меняется:
В 2026 году LLM-based синтез станет стандартом. Старые TTS-системы уйдут в прошлое. Озвучка видео нейросетью будет работать практически неотличимо от живого диктора.
Автоматический дубляж видео на другие языки
Автоматический дубляж — революция для кино и видеоиндустрии. Вместо найма дикторов для каждого языка система озвучивает видео автоматически на 20–50 языках.
Процесс:
Загружаете видео на английском. Система переводит озвучку (или вы загружаете готовый перевод). Генерируется озвучка на целевом языке с синхронизацией. Если вы загрузили образец оригинального голоса, модель воспроизводит его на новом языке.
Результат: фильм звучит так, будто оригинальный актер говорит по-русски, китайски, испански. Персонаж остаётся узнаваемым, но говорит на правильном языке.
Озвучивание видео нейросетью на разные языки раньше стоило десятки тысяч долларов. Теперь это дешевле в 10–20 раз и быстрее в 100 раз.
Компании используют: Netflix планирует автоматический дубляж для всех оригиналов. YouTube позволяет озвучивать видео на разные языки встроенным инструментом.
Говорящие аватары и синхронизация губ с голосом
Говорящие аватары — это синтетические персонажи, которые читают текст на экране. Их губы движутся синхронно с озвучкой, что создаёт эффект живого человека.
Как работает:
Вы загружаете сценарий. Система генерирует озвучку. Алгоритм синхронизирует движение губ аватара с озвучкой. Результат: аватар выглядит так, как будто действительно говорит.
Точность синхронизации в 2026 году достигает 98%. Губы движутся естественно, зритель верит, что это реальный персонаж.
Применение:
Платформы: Murf.ai, Synthesia, HeyGen предлагают говорящие аватары. Озвучка видео нейросетью здесь встроена в саму работу с аватарами.
Чего ждать в 2026 году: сценарии развития рынка озвучки
Сценарий 1: Массификация и доступность
Озвучка станет стандартным инструментом, как текстовый редактор. Каждый сможет озвучить видео за 10 минут. Цены упадут, качество возрастет. Озвучивание текста нейросетью станет бесплатным на базовом уровне.
Сценарий 2: Интеграция в платформы
YouTube, TikTok, Instagram встроят озвучку в платформы. Вы загружаете видео, платформа автоматически озвучивает его на выбранном языке. Нужно кликнуть одну кнопку.
Сценарий 3: Гиперпроизвод контента
Компании будут создавать контент в 10 раз быстрее. Вместо нескольких видео в неделю — десятки видео. Озвучка видео ИИ позволит это.
Сценарий 4: Рост регуляции
Законы о deepfake ужесточатся. Сервисы будут требовать согласие при клонировании голосов. Водяные знаки на озвученном контенте станут обязательными. Компании будут нести ответственность за misuse озвучки.
Сценарий 5: Гибридные решения
Озвучка будет сочетаться с видеоаватарами, музыкой, эффектами. Создание полнопрофессионального видео станет проще. Инструменты будут more integrated.
Что меняется для пользователя:
Вывод: озвучка нейросетью в 2026 году — это не экспериментальный инструмент, а основной способ создания контента. Те, кто начнёт использовать озвучку сейчас, будут впереди конкурентов когда новые тренды станут стандартом.

Максим Годымчук
Предприниматель, маркетолог, автор статей про искусственный интеллект, искусство и дизайн. Кастомизирует бизнесы и влюбляет людей в современные технологии.
